

Using ACL™ to analyze Fuzzy Duplikate (Levenshtein Distance)
In this article, I will take a closer look at a nice way to identify duplicates in ACL™ by using the (rather new) „Fuzzy duplicates“ command. It allows you to identify duplicates which are not fully identical. What this means, how to use it and what the pros and cons are will be discussed in this blogpost.
Duplicates in your data are a pain for the daily business. They slow down business processes, are the source for a variety of errors starting from materials management over to financials and accounting, and can cause – which is one of the worst cases - monetary loss through duplicate payments. You might have encountered the master data problem of companies on your own as a customer already; it may have happened to you that you received the same mailing twice from the same company, because you are in their system multiple times.
Almost one year ago I published a blog post here about the challenge of duplicate analyses in general, where I pointed out, that the simple question of “look for duplicate records” can actually be harder than expected. However, with one of the last ACL™ versions, the “FUZZY DUPLICATES” command was introduced, which is pretty powerful, yet easy to use.
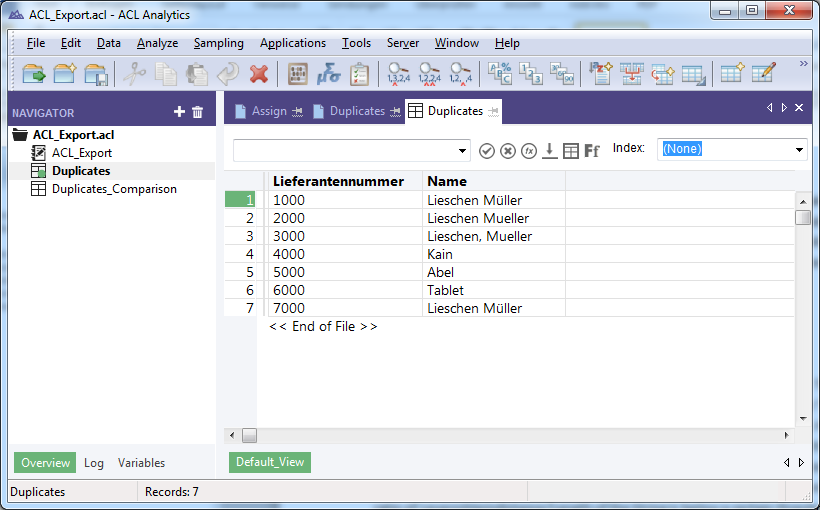
Let’s have a look at the following example. It contains a list of vendors, where one of the vendors appears more often, but written in a slightly different way. The name is “Lieschen Müller”, wich is a German equivalent for a dummy name like“John Doe” – but it works well for our example:
| Vendor number | Name |
|---|---|
| 1000 | Lieschen Müller |
| 2000 | Lieschen Müller |
| 3000 | Lieschen Müller |
| 4000 | Kain |
| 5000 | Abel |
| 6000 | Tablet |
| 7000 | Lieschen Müller |
You might be familiar with the DUPLICATES command in ACL™. It will identify duplicates based on one or more fields that will be checked for identical content. Running the standard DUPLICATES command the records 1 and 7 would be identified as possible duplicate:
| Vendor number | Name |
|---|---|
| 1000 | Lieschen Müller |
| 7000 | Lieschen Müller |
Levenshtein distance – The very basics
However looking at our data, you notice that we have the same vendor in there more often, with small spelling differences which might be caused by typos. This is where the FUZZY DUPLICATES command can be very useful. It is based on the Levenshtein-distance (also called “edit distance”) which gives a number that stands for the count of inserts/replacements or deletions that are necessary to transform one character string into another. This means, to transform “Stefan” to “Stephan” would require two (2) steps.
1. Replace the “f” with a “p”,
2. Insert “h”
(Of course you could also replace the “f” with an “h” and then insert the “p”, which would be two steps as well.”)
Threshold 1 – Maximum Distance
When identifying duplicates using the FUZZY DUPLICATES command, it makes sense to specify a threshold for that distance. Any distance above that limit will not be considered as duplicate. This makes sense, as “Stefan” has six letters. That means, doing 6 changes could turn “Stefan” into any other 6-letter-word. In other word, the Levenshtein distance between “Stefan” and “Charly” would be 6. So we could think about using a threshold of “3” for our example.
Threshold 2 – Ratio of distance to character string length
On the other hand, not only the count of changes is an important aspect. There might be very short words, where the distance always be below threshold. Imagine the words “Joe” and “Sam” – to transform one into another the distance is 3 (so it would be in our result). However as the length of the word only is 3, again these can be fully transferred into another word that differs completely. This is why ACL™ considers a percentage as well, which divides the distance by field length. In the last case it would be 100%. This can also be used as limit, to only identify records as duplicates where the ratio of (Levenshtein distance/Length of the String) is below a certain threshold.
Appliance in ACL™
The following screenshots show you how the command looks like in ACL™ based on the example above.
I imported the example table to ACL™ using the “IMPORT EXCEL” functionality. The data in ACL™ 11 looks as follows:
To apply the FUZZY DUPLICATES command, I go to the menu via “ANALYZE -> FUZZY DUPLICATES”. A dialog pops up which allows me to enter the parameters. Most of them we already discussed when talking about the Levenshtein logic and the thresholds that usually make sense considering.
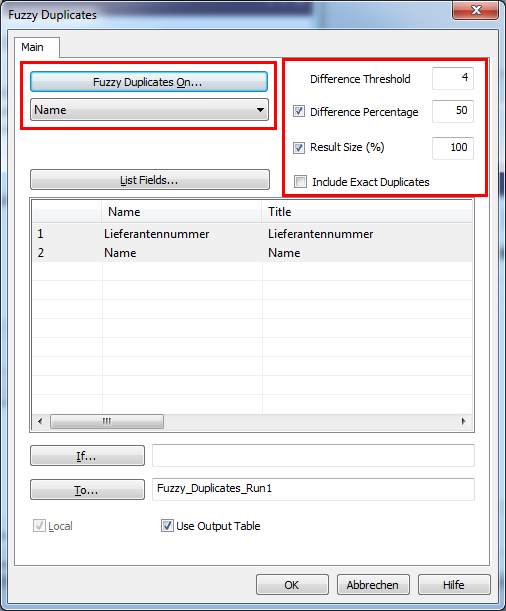
On the upper left corner you can specify the field (or fields) that should be used as base for the FUZZY DUPLICATES analysis. On the upper right corner you can specify the distance threshold (4 in our example) and the difference percentage (50 % in our example) as discussed. You have two additional options. One allows you to limit the result size. This prevents the result from being generated, if it would be too big. Especially when you are trying out different thresholds, it could happen that you enter values which are just too generous. If you analyze 100,000 master data records, and the result would be 90,000 potential duplicates, it just might not make sense.
The second parameter allows you to decide whether you want to include exact duplicates or not. (In terms of Levenshtein distance a distance of zero would mean “exact duplicate”).
The result will be a new table named “Fuzzy_Duplicates_Run1” and looks as follows:

ACL™ identifies the records 1, 2 and 3 as possible duplicates. It groups the data and assigns group numbers. In our example we only have one group of duplicates which consists of vendors number 1000, 2000 and 3000.
Let me show you why our result looks like this by giving you the distance and percentage for other comparisons that were made:
| Vendor number | Name | Vendor number | Name | Distance | Percentage |
|---|---|---|---|---|---|
| 1000 | Lieschen Müller | 7000 | Lieschen Müller | 0 | 0% |
| 2000 | Lieschen Müller | 3000 | Lieschen, Müller | 1 | 6% |
| 1000 | Lieschen Müller | 2000 | Lieschen Müller | 2 | 13% |
| 1000 | Lieschen Müller | 3000 | Lieschen, Müller | 3 | 20% |
| 4000 | Kain | 5000 | Abel | 4 | 100% |
The table above does not contain all possible comparisons, just selected ones. Kain and Abel are not in our result. The difference between the two names is only 4, but this is a ratio of 100% (distance divided by string length, so 4/4 = 1, which is 100%).
The distance between the different Lieschen Müller – records is 0, 1, 2 and 3. The exact duplicate is not contained in our result, as we did not select the option to “Include exact duplicates” as well (see dialog above). So our one group of duplicates contains the vendors number 1000, 2000 and 3000, as neither distance nor percentage are exceeding the thresholds we entered as parameters. If we would have ticked the “include exact duplicates”-option, our group would have contained all four Lieschen Müller records.
What happens if we select a smaller distance, let’s say a distance of 2 as threshold?
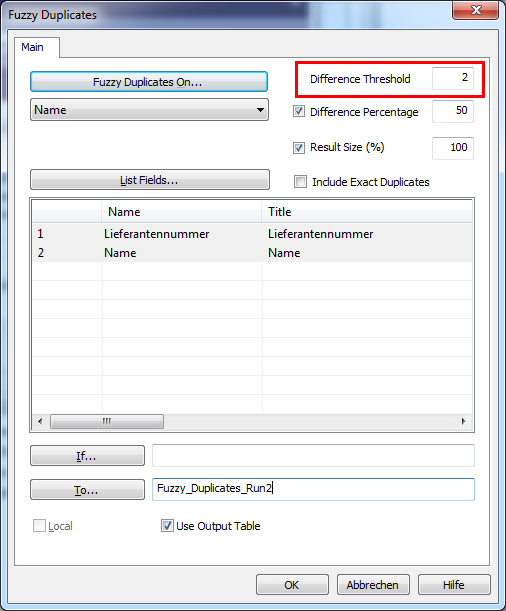
The result looks as follows:
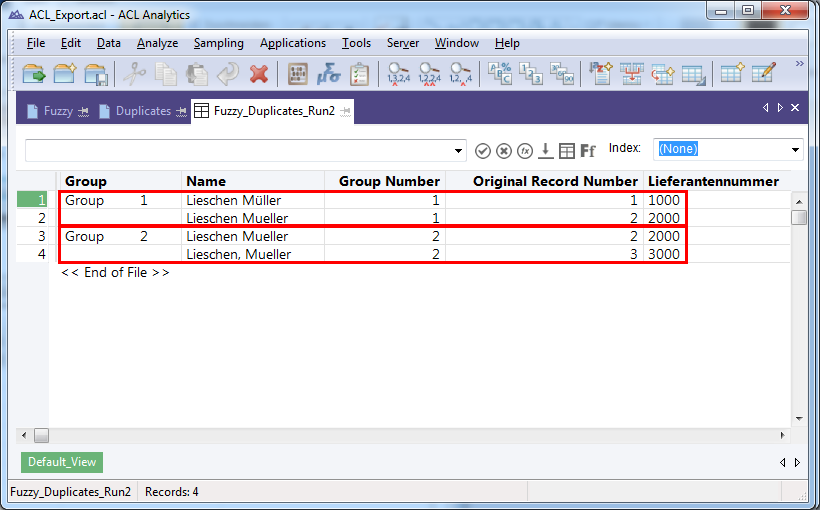
Now we do have 4 result records and two groups. Limiting the distance threshold generated more results instead of less, but why? To find out, let’s have a look at the comparison table again:
| Vendor number | Name | Vendor number | Name | Distance | Percentage |
|---|---|---|---|---|---|
| 1000 | Lieschen Müller | 7000 | Lieschen Müller | 0 | 0% |
| 2000 | Lieschen Mueller | 3000 | Lieschen, Mueller | 1 | 6% |
| 1000 | Lieschen Müller | 2000 | Lieschen Mueller | 2 | 13% |
| 1000 | Lieschen Müller | 3000 | Lieschen, Mueller | 3 | 20% |
4000 | Kain | 5000 | Abel | 4 | 100% |
The distance between vendor 1000 and 2000 is 2, so not exceeding the threshold. The distance between 2000 and 3000 is 1, also not exceeding the threshold. However the distance between 1000 and 3000 is 3. This is bigger than the threshold of 2 which we assigned. Because of this, ACL™ identifies two different groups of duplicates, [1000, 2000] and [2000, 3000]!
This also corresponds with the general challenges that I pointed out in the article “Identifying master data duplicates – Simple, isn’t it? ”. The very same record can be in different groups of duplicates.
Three technical, but important details
- First of all, take care, the command is case sensitive. That means “John” and “john” would be considered to have an edit distance of 1, to replace the first capital letter! If you want to avoid this, convert the field you want to test by using ACL™ functions like UPPER(), lower() or Proper().
- Secondly corresponding to the FUZZY DUPLICATES command there is a function in ACL™ that allows you to calculate the Levenshtein distance between two fields, it is called LEVDIST(). I used it to calculate the distance in the example which I put there for explaining the details.
- As third point I want to emphasize that a blank is also treated as character just like any other, so make sure to use the TRIM-functions ALLTRIM(), LTRIM(), or TRIM() in ACL™to clean your fields first to avoid unexpected results.
Summary
The “FUZZY DUPLICATES” command is a cool feature which allows you do to powerful duplicates analyses in a very easy way. When having a closer look at the parameters like we did in this article, it is not difficult to understand and apply. You will be able to detect classical duplicates which happened because of simple typos when entering the data. However you should be aware that the number of false positives can increase dramatically, as you will get records in your results which are (as intended) not 100% alike – like “Stephan” vs. “Stephanie”, they may have a Levenshtein distance of only 2, but are two different persons. It is like being able to fish with a bigger net than before – you might catch more fish, but you have to spend more time sorting other stuff that got into the net. Give it a try, it is a great feature and you will have findings that you were not able to identify beforehand that in such a quick and easy way.
For any comments on this article, feel free to write us at info@dab-europe.com. To contact the author you can also use LinkedIn or XING (you may have to login first before you can access these links).
LinkedIn: http://de.linkedin.com/pub/stefan-wenig/54/1b8/b30