

Process Mining – Why, what for, how?
While process mining has been a topic of discussion for some while, interest has recently intensified. Google currently shows 1,100,000 hits for searches on the subject, and Gartner’s most recent “Market Guide for Process Mining” published in June 2019 lists 19 suppliers in its “Representative Vendors” section.
We have been involved in the details of the subject for some time now. In our first blog posts dating back to 2015, my colleague Martin Riedl discusses event logs in detail.
In this blog post, I first provide some high-level information on the underlying technology from a data perspective. I then explain where process mining is positioned compared to traditional, transaction-based data analytics, and point out a few potential pitfalls to be aware of during the implementation process. A brief interim conclusion is followed by a description of two suppliers with whom we cooperate. I explain why, and outline the differences which we believe can help you when choosing a tool. My colleague Robert has already written a more detailed report about one of these partners for you.
Introduction
Good processes help create added value within a company and optimise internal workflows. Modelling process workflows is also an integral element. A specification language such as BPMN (Business Process Model and Notation) helps to visualise (or document) processes.
Documenting processes based on the understanding/opinions of relevant individuals who know the process well – or sometimes of stakeholders who describe how they hope the process might look because it is similar to how they think it should look – is one thing, but documenting them based on the actual data present in the system is another matter.
This is also a decisive factor for process mining suppliers and fans: mapping the actual status from a process perspective with the ability to determine process workflows and to identify and improve weaknesses. Improvements can, for example, take the form of changes to operational processes, better support for individual sub-processes or, on the IT side, automation through RPA Robotic Process Automation. The relevance of this last point is reflected in the sometimes close collaboration between RPA solutions and process mining suppliers, such as MINIT or PAF.
A central element of process mining solutions is the process graph. The example below shows this visualisation of the process:
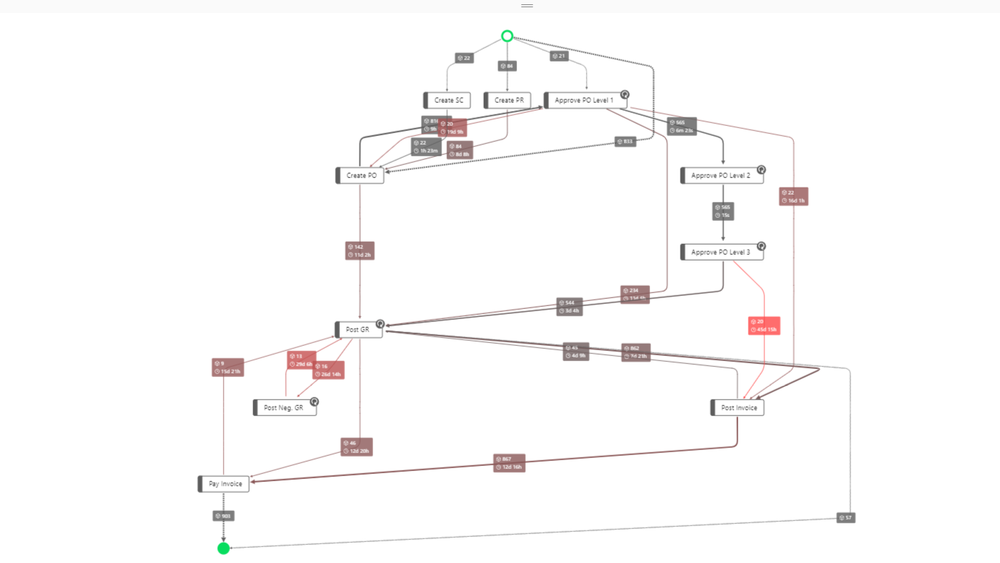
Graph in PAF
Here is another example:
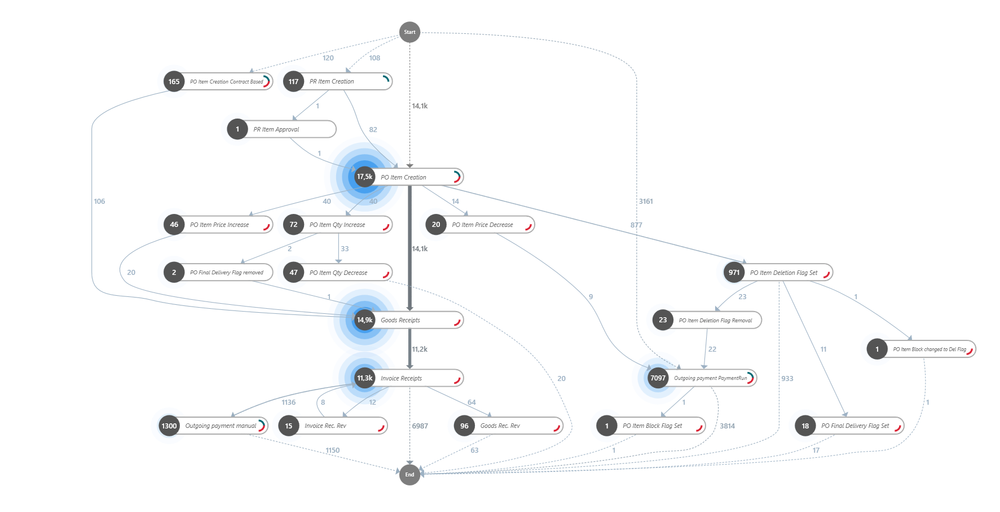
Graph in Minit
The graphs are generally also interactive, i.e. the event iterations can be viewed in animated form, additional information can be inserted or removed, filters can be set to selected steps or process areas, or the complexity of the graph can be increased or reduced through the maximum number of variants shown.
As well as the basic functioning of the tools, this chapter has already mentioned the two process mining suppliers with whom we cooperate closely: Process Analytics Factory (PAF) and Minit. Further details on both companies are provided below in the chapter “Deciding on the right tool”.
Technical aspects - the database
As seen above, a process mining graph is one of the desired outputs when using a process mining solution. Generally, these graphs cannot be generated immediately the software is installed. Process mining tools work with event logs. This is a data view, prepared based on the raw data within the company, which has certain attributes required to create a process graph. Specifically, these include the case ID, event identifier, and timestamp.
The software (or the underlying algorithm) uses these data to create the corresponding graphs. The time (timestamp, ideally as granular as possible) at which a certain object (case, e.g. purchase order item) passed or did not pass through which stations (events, e.g. system, approval, delivery).
In addition to these three mandatory elements, it is generally possible to define additional attributes (monetary amounts, business partner IDs and names, etc.) and so make it easier for the end user to interpret the result.
The event logs prepared in this way are thus based on the raw data within the company, which are often stored in tables of a database. They can originate from an integrated system (e.g. SAP). However, data from different systems can also be combined into an event log (e.g. if the purchasing process takes place in an upstream system X and financial accounting, which is responsible for paying invoices, uses system Y). This naturally requires that the events, cases and timestamps can be appropriately defined across systems. Creating an event log therefore requires existing knowledge of processes and of how they are mapped by systems. It also requires the technical ability to combine them into an event log. Only then can the pool of raw data be correctly combined. For SAP systems, for example, it helps to know that purchase requisitions are stored in the table EBAN, purchase order documents in EKKO and EKPO, and the purchase order history in EKBE. As well as knowledge of tables, it is also important to know which fields are suitable as a timestamp, how the individual events (initial creation, release, goods receipt, invoice receipt, etc.) should be designated, and which is the most suitable attribute to identify a case.
An overview of the database is shown below:
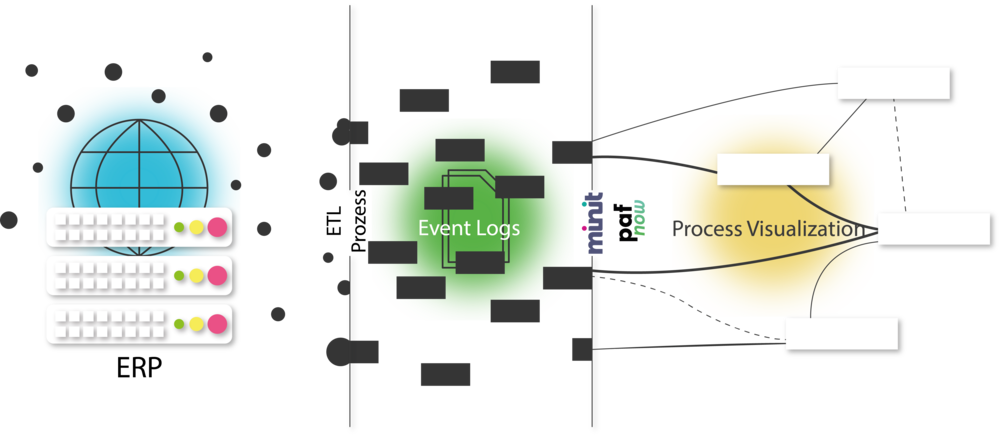
If you would like more detailed information on event logs, my colleague Martin Riedl has already provided some insights on the topic (the blog remains relevant today even though, as mentioned above, it dates back to 2015).