

Process Mining Part 2 - The Eventlog
For a number of years now process mining has been a subject in the world of data analysis that analysts are increasingly focused on. We too have already devoted a blog article to this methodology and gathered initial experience in projects of a different scale and with different tools. Through this series of articles I would like to offer insight into the experience we have managed to gain.
Introduction
Hopefully blog post #1 of this short series of articles gave you a first impression of process mining, also explaining some basic process mining concepts. One of these was of course the event log – the central data basis of any process mining project. In this second part of the series I would like to explain the creation of an event log based on purchasing data of an SAP ERP system, and at the same time point to the difficulties that show, plus the peculiarities you need to watch out for.
Structure of the event log
As already broached in blog post #1, an event log requires certain mandatory fields, but can be enriched by further fields that are not absolutely necessary. The more extra information you put into the event log, naturally the better are the possibilities to filter and analyze when working with the data later. But it is essential to concentrate on fields that are really necessary, to keep the event log as lean as possible and not risk performant data processing by the process mining tool.
Absolutely essential fields of the event log are:
- Case ID: A case is a cohesive process run. I will go into that in more detail later. The case ID is the unique feature, usually a value you can derive directly from the data of SAP ERP (eg combination of purchasing document number and item).
- Type of event: Each event type requires a unique description (eg create purchase order, approve purchase order).
- Timestamp: A timestamp indicates when an event was logged in the system.
What is important here is that every single event to be presented later by means of a node appears in this event log as a separate data record. Assume we are dealing with 100 processes (eg 100 purchase orders) and each process consists of 4 events (creation, approval, invoice receipt, goods receipt), the event log will contain precisely 400 data records. I certainly do not need to mention extra that in reality things are not that linear and simple.
To be able to filter further in the process image generated by the process mining tool, it may often be a good idea to include further features in the event log. Deciding which features are suitable for the purpose depends to a certain extent on definition of the case ID. If you create an event log based on purchase order headers (more about this later), there is little sense including a material number or material group that is maintained at item level.
Based on SAP ERP data the following attributes are conceivable as an extra feature in the purchasing process:
- User who triggered the event
- Vendor of the purchase order
- Purchasing organization, company code, plant
- Material number, material group
When importing the event log into the Disco tool you can differentiate between entering these fields as a "Resource" or as "Other data field". Resources – in contrast to other data fields – are presented both singly and combined in Disco statistics. You will learn exactly what that means in one of the next articles when we look into the functionalities of Disco.
The technical side of creating
At this point I should say that none of the process mining tools I am familiar with automate creation of this event log, but set up the work of actual process mining on this data set – no matter how created – and more or less take this for granted as a premise. Nevertheless, most providers naturally also offer creation of the event log – usually by "conventional" technology such as SQL routines. In my case of SAP ERP data, which we will again process with Disco, I undertook creation of the event log by ACL data analytics software – a procedure that has fully acquitted itself for our purposes.
A further major hurdle in process mining projects is often the actual extraction of data from the source systems. This source system landscape can naturally fast become very heterogeneous when you take certain processes. Our experience shows that this problem is not too frequent among customers who work with SAP: Here the processes are logged in the SAP systems from start to finish very often homogeneously, and are thus available as raw data ready for extraction.
Nor is the actual extraction a problem in our case because we have solved it for a number of years now by our dab:Exporter product, and extract enormous quantities of data from SAP systems with resource efficiency. In our version 3.0, which has been a market success for one year now, we also devoted attention to subjects like delta extraction that are essential for a continuous analytic approach that should also be used in process mining.
The entire subject of data extraction is worth considering in a separate article. Since this is not automatically linked just to process mining but also relevant for "normal" data analytics projects, I will publish an article on the subject soon aside from this series.
What is a case / definition of case ID
Before you start to create an event log, you should be clear on what defines a case. We need a leading process element, so to speak, with which we can link the events or to which we can allocate the events.
Taking SAP ERP purchasing data I will consider in concrete terms why some elements are more and others less suitable to act as a case:
- Purchase requisition
The purchase requisition would be the first imaginable element in the process chain that could define the case. Not forgetting however that not every purchase requisition becomes a purchase order, and not every purchase order is based on a purchase requisition. So in practical terms the purchase requisition is perhaps less suitable. - Purchase order
At first glance the purchase order seems to be best suited to serve as a case, representing as it does a purchasing transaction that we actuate with a vendor. In the unique order document number in the SAP system we also have the perfect unique code for the case ID. Or maybe not? Looking more closely, we see that with approval there actually is an important element enacted at the level of header data – ie really pro purchase order. But there are many other possible events that can also be exciting, eg price changes, invoice receipt and goods receipt – although these are all item-related. Complicating matters, after creation of a purchase order we can add single items to it days or even weeks later – that being a challenge when it comes to creating a sound and informative event log. - Purchase order item
To come straight to the point: In my opinion the purchase order item is the element best suited to identify a case. Why? For one thing an upstream step like the purchase requisition is always item-related, and the further events like changes, invoice receipt, etc always relate to a purchase order item. A new creation is also in principle simple in that I give all items initially found in a purchase order the date of creation of the purchase order and identify those added through the update logs of SAP. Here a combination of order document number and item number consequently serves us as the case ID.
So we decide to use the purchase order item as the case. Nevertheless we are inquisitive and want to at least take a look at the differences in the process maps between "purchase order" case and "purchase order item" case.

Figure 1 - Process map of "purchase order header" case (100% events / 15% paths)

Figure 2- Process map of "purchase order item" case (100% events / 15% paths)
Let us look at the differences between the process maps without going into too much detail, and one thing is very apparent. In use of the purchase order number as the case ID, ie seen at header level, we have very many repetitive events, eg the same invoice receipts following one another – recognizable here by the thick arrows leading back to the output box. This is fully understandable when you think that just the creation of a purchase order with 5 items results in 5 consecutive events. Of course these cases could have been collected under one number and the same timestamp, but by the invoice receipts at the latest such repetitive events are no longer easy to eliminate.
Admittedly, the purchasing area in SAP ERP is now relatively well manageable. The whole thing becomes more complicated in the order to cash process. Here, in addition to various document categories that reference one another (eg contracts result in orders and these in turn can result in credit memo requests or returns), we also have delivery documents and billing documents. Defining the right case now may even depend on the business model of the unit to be investigated.
The events
The second essentially important decision to be taken in data editing is definition of the events themselves. You cannot create a clear-cut process map until you have properly defined not just all relevant but only the really meaningful events.
Definition of these events also depends to a certain extent of course on the structure of the given data. If an ERP system includes no approval procedure for purchase orders for example, there is no sense in defining such events. Proper allocation of a timestamp is an entirely self-contained question that must be clarified, and I will go into this further below.
Staying in the SAP ERP world, the events below are presented by the SAP tables in the standard:
- Creation of purchase requisition
- Approval of purchase requisition
- Creation of purchase order or purchase order item
- Approval of purchase order
- Changes in price and/or quantity
- Change of deletion indicator
- Change of delivery completed or final invoice indicator
- Goods receipt
- Invoice receipt
Here are a few thoughts on some of these events.
Approval (purchase requisition or purchase order)
Purchase requisitions in SAP are item-related by data model, ie here you have approval at item level, whereas for purchase orders approval is for the complete purchase order, where we speak of a header event. Here we duplicate the approval simply by item. Something more important to be mentioned is in my opinion the fact that in the SAP approval process we may not only have an approval but possibly also reversal of an approval or rejection. For our event log that means we have to define a separate event for each of these steps.
Changes in price/quantity
Here the situation is similar. A change can mean both an increase and a decrease in price or quantity. The effect is the same – the order value of the item changes. So you must decide whether you want to work with 1 event (change in order value), 2 events (increase or decrease in order value), or even 4 events (increase/decrease in price and quantity). In our example I opted for the 4-event variant for the sake of maximum transparency.
Invoice receipt
Because of the socalled 3-way match in SAP where, in simple terms, the invoice value is compared to the order value and goods receipt, it is possible for an incoming invoice to be blocked already when posted inward. That shows the way to different possibilities for event definition:
- You can ignore it and just treat everything as invoice receipt.
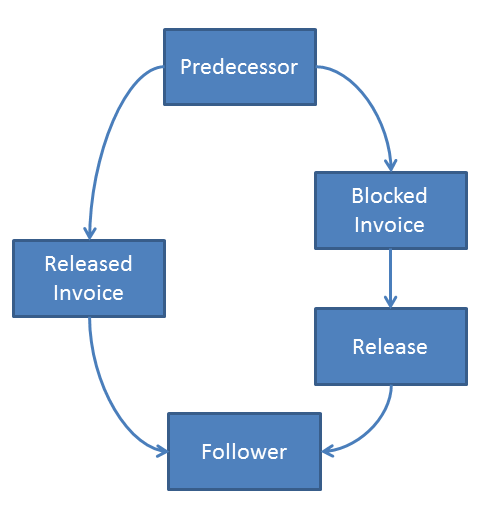
- You can define separate events for invoice receipt, block invoice and approval of invoice.
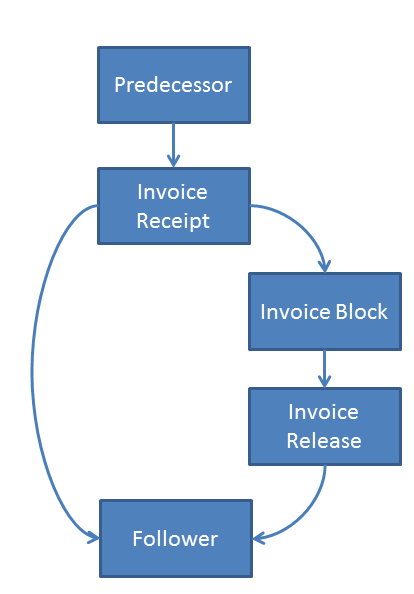
- You define one event for invoice receipt, one for blocked invoice receipt and one for approval of invoice.
The difference between b) and c) then is that in variant b) blocking and approval first run through an event of the same kind (ie through a box), while in c) two boxes are used for invoice receipt, of which only the blocked one can lead into the approval event (see graphics).
Just these three closer explanations show that defining events takes a lot of care and that explicit knowledge of SAP data structures is needed. An iterative approach is certainly not out of place. In other words, define the events on a sheet of white paper, see what the database actually produces, and possibly find further data tracks leading to the definition of further events.
In our example we have occupied ourselves exclusively with the real purchase orders (document category F). For a really comprehensive picture you also need basic contracts (document category K) and scheduling agreements (document category L).
The right timing
Last of all we must give our events the right timestamp. As trivial as it may sound, this is sometimes not that simple. Not all SAP tables produce a timestamp together with the corresponding date.
Supposedly it is easiest if you can generate the event from the SAP change documents, because there you find a timestamp in the CDHDR header table next to the date. Nor should you be led astray by the expression "change tables". In part you can find in the tables reliable dates and times for new creations. But this depends on the change document object.
In the case of dates in the transaction tables you must ensure that these really are unalterable dates that reflect logging of the event by the system. As an example take the CPU date (CDUDT) in invoice and goods receipts. Use of the document date (BLDAT) for example will "enhance" the process maps. On the other hand, sometimes a manually alterable date in process maps can be interesting, eg to identify cases where the document date of invoice receipt comes before the date of creating this purchase order item. So here in data editing it can be necessary to adopt a certain amount of flexibility in your approach and make selection of the date fields controllable, or start straight away by working with a number of different date columns, and decide what date to take when importing into the process mining software.
Finally it must be said that SAP can give you a tough time for many a date. For example, I was unable to find a uniquely definable creation date of a purchase requisition. The date in the EBAN table logs all changes and is thus a date of the last change, and the creation of a purchase requisition item, unlike the purchase order items, is NOT logged in the change documents. If a reader of the blog has any tips on this, I would be thankful.
Timing will again be a subject the next time because it is not only relevant in just timestamping events. Quite generally it is a matter for special care, like in the timed restriction of data extraction and editing, since every restriction naturally produces the risk of generating incomplete process chains. Next time we will look at this in the light of extraction and Disco.