

Process Mining Part 1 - a comprehensive view - foundations
For a number of years now process mining has been a subject in the world of data analysis that the analysts are increasingly focused on. We too have already devoted a blog article to this methodology and gathered initial experience in projects of a different scale and with different tools. Through this series of articles I would like to offer insight into the experience we have managed to gain. After explaining some basic terms I will take a look behind the scenes to make two points clear:
- In process mining the quality of results and their processing by the end-user hinge on the quality of preliminary considerations and conception.
- Data conditioning, cleanly defined and soundly conducted, is the basis for this.
Introduction
A first look at a process map generated by process mining tools usually results in interested decision-makers fast becoming full of enthusiasm and wanting to use such a tool under all circumstances. I too was very impressed to begin with, and could hardly wait to "delve" more into the technology and its application. This also has much to do with the fact that many process mining providers naturally pack only easily digested, catchy little pictures into their marketing literature. And the real, less attractive truth only comes to light when you take a second or third look. This rather ugly truth has a variety of somewhat derogatory names like "noodle soup" or "spaghetti", and is perhaps best illustrated by the graphic below.
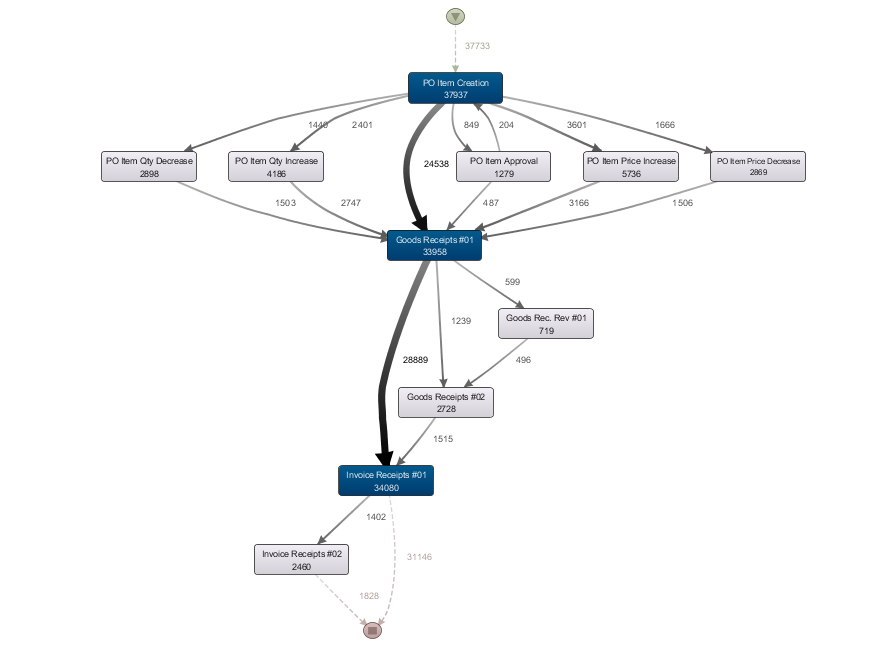
Picture 1 – Simple graphic example
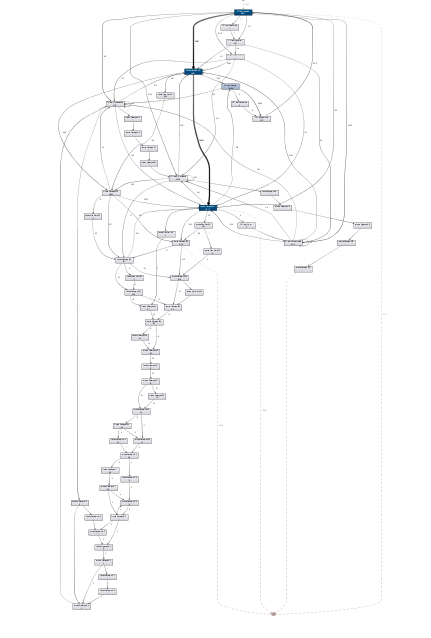
Figure 1 shows us a wonderful picture of a purchasing process with typical events such as creation and approval of an order, or goods and invoice receipt. What the map does not tell us, however, is that this process model only contains 15% of the events in the data set, and that only the most important paths in this 15% were visualized. The whole "wicked" truth of a really lived process then shows in Figure 2, based on the same data set but this time with 100% of the events and 100% of the paths. It goes without saying that working or checking is no longer possible faced with such an onslaught of information. For the skeptics – a map like this in all its confusing entirety is by no means an isolated case. And the processed data set consists of an SAP company code with just under 24,000 purchasing document headers, 53,000 document items, about 80,000 goods receipts and the same number of invoice receipts. So it can be classed more as a "smallish" data set.

Picture 2 – "noodle soup"
In all fairness it must be said that this absolute clutter is largely due to showing 100% of the paths. If, as the common tools luckily allow, you reduce the degree of detail with which the paths are shown, the picture usually starts to look less forbidding, as in Figure 3. This is a presentation of ALL events, but only with the most important paths (10% in my example).
Picture 3 – process map - 100% events - 10% paths
Figure 3 shows that a relatively large number of different events exist for this purchasing process. The reason being that invoice and goods receipts were numbered consecutively. In other words, if five different invoice receipts exist for one purchase order item, five different events (invoice receipt #1 thru #5) were generated. Of course that increases the number of existing events, but offers much more process transparency, and avoids one problem of process mining that at this juncture I will call "repetitive" events. These are events that directly follow themselves and are then usually shown by an arrow back to themselves (Figure 4).
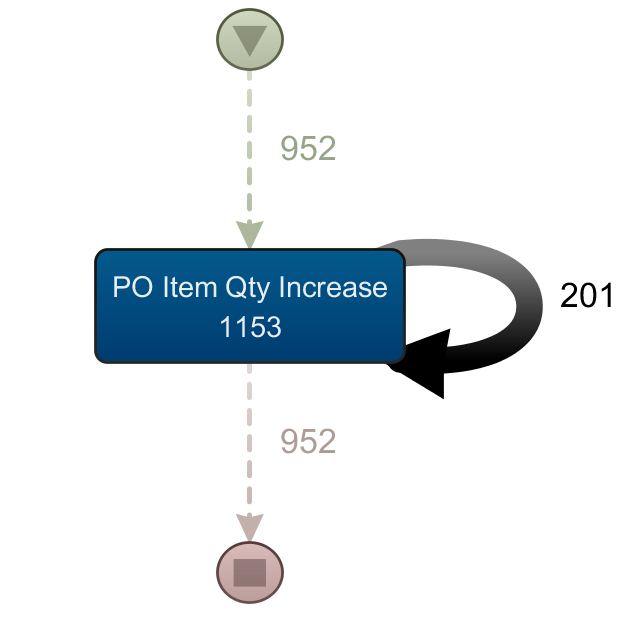
Picture 4 – repetitive event
These repetitive events and how to work with them will be dealt with in more detail in a later post. First we want to explain a few basic terms and the question of the tool used here.
Disco – the tool of my choice
The market for process mining solutions is growing but still "manageable". To obtain an independent view, refer to this Wikipedia article. Without tackling each of all the tools, and thus cannot really assess them, for my excursions into process mining I used Disco from Fluxicon. For one thing it is easy to install on a standard computer because it needs neither a server component nor a database. Secondly you can work with it very intuitively even if you do not have a great deal of experience in the matter.
Explanation of terms
Before going into more detail in the following articles, I think it is important to explain a few terms that we will repeatedly come across.
- Event log
- Event (or case)
- Case ID
The event log
The data basis of a process mining project is always the socalled event log. This contains a listing – not necessarily in a sorted sequence – of all events of the process or, better said, of the events you have defined in data conditioning. Every event per case (we will look at cases straight afterwards) represents a data set that must have at least the following columns:
- Case ID (see below)
- Type of event (eg purchase approval, price change)
- Timestamp (when an activity was executed)
In addition to these three necessary columns, you can define extra fields that may then be used later, eg for further filtering in the maps. It is also imaginable, in as much as the data set allows it, to work with start and end times for events to visualize this later in the software.
The event
As already said, the event log consists of the individual events of the process you are looking at. Definition of these events and appropriate implementation in the data conditioning is the first challenge facing you. Without claiming to be complete, we have defined the following events for our procurement example:
- Creation of purchase requisition
- Approval or refusal of purchase requisition
- Creation of purchase order or particular purchase order item
- Approval or refusal of purchase order
- Price or quantity adjustments
- Goods receipt or reversal
- Invoice receipt or cancellation
Item 3) makes it clear straight away that it is not so easy to define in the events whether you mean header data or item data. But this will be of central importance especially for the next term – the case ID – and something we keep seeing in the course of the series.
The case and the case ID
Once you have defined the events you want to visualize in the process, you are confronted with the next problem: definition of the actual case. Every distinct process pass, ie in our example ideally a purchase requisition finishing in goods and invoice receipt, requires a unique case ID. Depending on what is seen as a case and selection of this case ID, the graph may act differently later. The fact that definition of the case ID is no trivial matter is shown by the following considerations based on SAP purchasing data.
- A purchase requisition has per se no separate header data in SAP and is thus always line-related.
- A number of purchasing document items can be generated from one purchase requisition. However, a number of purchase requisitions can also be comprised as one purchasing document item.
- Approval of purchase orders is always at header level.
- Changes of price or quantity are naturally item-related.
- Goods receipt and invoice receipt are likewise item-related and can of course appear in an 0-n relation, ie one order document item can have a number of goods receipts and invoice receipts.
This illustrates that it is by no means easy firstly to define the case itself (purchase order header or purchase order item?), and secondly to assign the appropriate events to a unique case ID.
We will also take a closer look at this problem in the course of the articles, comparing different constellations and observing the effects in the process mining tool.
Example data
As already mentioned, this is a smallish data set for SAP® clients with the following quantity structure:
- 24,000 purchase orders with 53,000 document items
- 80,000 invoice receipts and 80,000 goods receipts
- Approx. 15,000 purchase requisitions
In the first step, intentionally for this article, I decided to leave out the complete FI page and end with invoice receipt or the corresponding MM transactions of SAP®. Including FI transactions with outgoing payments and the SAP® clearing system in all its flexibility would have created complexity that was not conducive to devising first fundamentals.
Looking ahead
In my next posts I will go into the following topics:
- Challenges in case definition (header vs item or what will be the leading element)
- Timing or correct accrual in time
- Special features in defining or creating certain events
- Possibilities of Disco
- Frequency vs performance presentation
- Possibilities of filtering
- Working with resources or further data fields
Finally, Dr Anne Rozinat of Disco producer Fluxicon has agreed to contribute a guest paper to the series telling of concrete project experience.
I look forward to your feedback and further suggestions and ideas on the subject of process mining.