


Machine Learning und Künstliche Intelligenz – Alles nur Hype. (?) Teil 2
Ich hoffe Ihnen hat unser erster Beitrag in unserer Reihe über Machine Learning gefallen. Sollten Sie ihn verpasst haben - kein Problem. Hier können Sie ihn nachlesen.
Im zweiten Teil dieser Blogreihe fokussieren wir uns auf folgende Themen:
- Einleitung: Von globalgalaktischen Themen bis hin zu Audit, IKS, Datenanalyse und Risikomanagement (in diesem Beitrag behandelt)
- Brücken bauen: Es beginnt vielleicht mit einer Enttäuschung - von Ihren Daten zu Machine Learning Algorithmen
- Content is (auch hier) king: Kreativität kommt später - nur die konkrete Anwendung schafft Mehrwert.
- Drei Anwendungsbeispiele: a – Alter Wein in besseren Schläuchen; b – Brandneu; c – Anders.
- Fazit
2 Brücken bauen: Es beginnt vielleicht mit einer Enttäuschung
Machine Learning Algorithmen sind nicht wirklich neu. Auf Grund der in der Einleitung beschriebenen Aktualität des Themas ist aber das Interesse daran im Moment enorm. Zahlreiche Softwarehersteller und IT Unternehmen reagieren mit einem entsprechenden Angebot. Amazon bietet die AWS (Amazon Web Services) mit entsprechenden Tools und Services sowie in dem Zusammenhang geeignete Algorithmen an.
Wir arbeiten ja auch intensiv mit der ACL Robotics Lösung von Galvanize. In dieser wurde schon vor geraumer Zeit der K-MEANS Algorithmus als Clusteringverfahren eingeführt (neben den Kommandos Train und Predict die wiederum, ein Set an Algorithmen nutzen). Hierzu hat unser Kollege Moritz ebenfalls eine Beitragsreihe mit integriertem Workshop verfasst.Hier finden Sie Teil 1.
Wieso aber habe ich plakativ geschrieben „Es beginnt vielleicht mit einer Enttäuschung“? Ein Beispiel: Nach der Einführung des K-MEANS Algorithmus haben uns Kunden kontaktiert, die gerne – ins Unreine gesprochen - analysieren wollten, ob sich Ihre Geschäftspartner-Stammdaten, textuelle Beschreibungen ihrer Auditfindings oder Buchhaltungstransaktionen mit dieser Analyse clustern lassen, und wie das Ergebnis aussieht. Eine erste Ernüchterung kam dann auf, als klar wurde, dass der K-MEANS Algorithmus als Basis numerische Attribute benötigt.
Es ist also eine Transformationsleistung notwendig, um in Sachen Datenbasis flexibler zu sein. Hier kommt also schon der erste notwendige Schritt ins Spiel: Abhängig von Intention und gewähltem Algorithmus müssen die Daten umgewandelt werden. Hier helfen wir Ihnen mit Transformationen weiter: Nicht mehr Tabellen und Felder sind Gegenstand der Analyse, sondern „Derivate“. Diese enthalten die Information, die in ausgewählten Feldern enthalten ist – jedoch für ML-Algorithmen direkt verwertbar. Diese Information ist also nahezu vollständig losgelöst von der Semantik der ursprünglichen Daten und auf die Verwendung durch spezielle Algorithmen optimiert.
Kurzum – Sie müssen sich bewusst sein, dass Sie Ihre Daten ggf. nicht direkt in Machine-Learning Algorithmen verwenden können. Die dafür notwendige Transformation können Sie mit entsprechendem Know-How selber vornehmen lassen, oder auf unseren vorgefertigten Content zurückgreifen. Dieser ist nicht nur technisch optimiert, sondern wurde auch inhaltlich auf die spezifischen Anwendungsfälle hin zugeschnitten und optimiert.
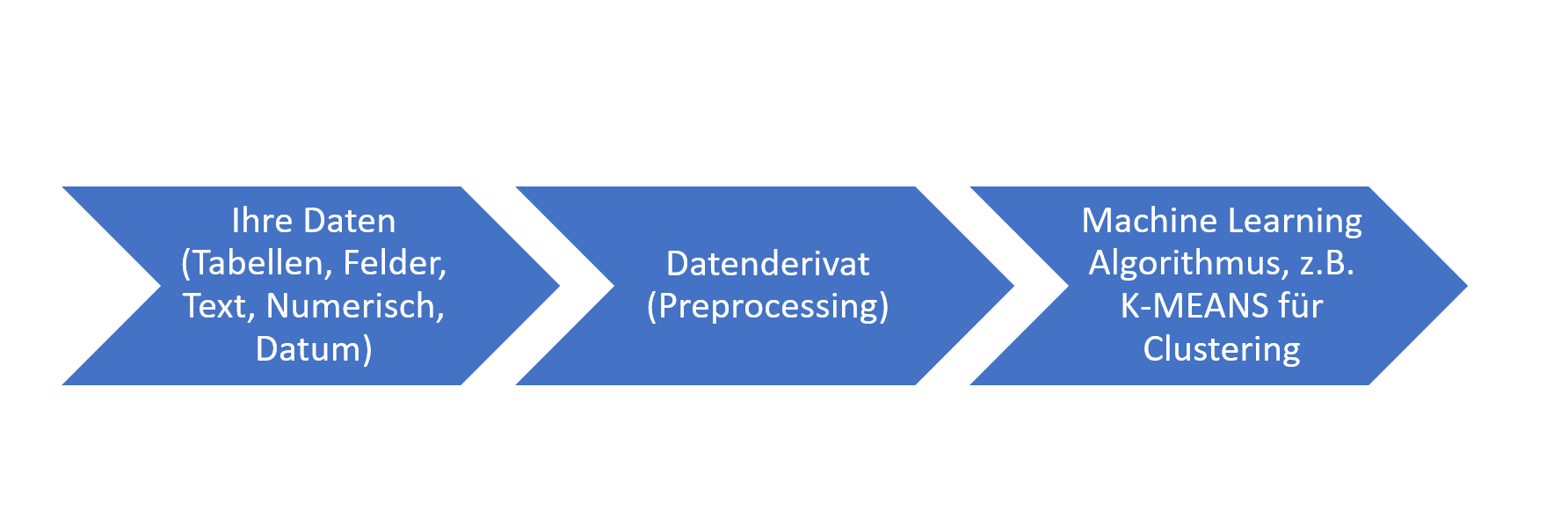
D.h. wir bilden diese Datenbasen (Derivate) für Bereiche wie Kreditorenstammdaten, Einkaufstransaktionen oder Buchungen in der Finanzbuchhaltung oder Materialbewegungen. Dabei fließen in die Transformation diejenigen Attribute ein, die aus unserer Sicht für die Folgeanalysen relevant sind; mittels geeigneter Methoden transformieren wir diese so, dass die so erzeugte Datenmenge dann „ML ready“ ist.
3 Content is king – Nur die konkrete Anwendung schafft Mehrwert
Im vorherigen Abschnitt wurde die Relevanz der Transformation erklärt. Manche Algorithmen bedingen eine entsprechende Vorverarbeitung (Preprocessing) der mittels ML Methoden zu analysierenden Daten. Wie besprochen achten wir darauf, die Daten im Rahmen des Pre-Processing auch inhaltlich zu optimieren: Wir lassen die aus unserer Erfahrung nach semantisch relevanten Daten einfließen, nehmen ggf. eine Aufbereitung und Bereinigung vor und transformieren diese dann in ein entsprechendes Derivat, das dann z.B. direkt in Clusteralgorithmen wie dem K-MEANS Algorithmus verwendet werden kann.
Positiv formuliert sind der Kreativität an dieser Stelle nahezu keine Grenzen gesetzt, wenn es um die Weiterverarbeitung geht. Kritisch betrachtet kann sich aber schnell die Frage stellen, was denn nun konkret an Mehrwert geschaffen werden kann.
Natürlich ist es spannend, einen völlig neuen Blick auf seine eigenen Daten zu bekommen. Ansprechend visualisiert ergeben sich hier vielleicht Muster, welche man so nicht erwartet hätte und die durchaus spannend aussehen.
Was macht man aber nun mit den Ergebnissen? Eine der Forderungen z.B. des letztjährigen Gartner Data Analytic Summit war „from insight to action“; sprich mit aus den Ergebnissen aus Datenanalysen auch konkret Handlungen abzuleiten und durchzuführen. Dies wird dann schwierig, wenn sich die Muster (z.B. die gefundenen Cluster) nur schwer interpretieren lassen. Man erzeugt ein vermeintlich spannendes Bild an Clustern – allerdings fehlt einem jede Idee, was genau die Aussage daraus ist, ganz zu schweigen von den konkreten Handlungen, die sich daraus ableiten.
Konkreten Mehrwert generiert man bestenfalls mit dem zu erreichenden Ziel vor Augen:
- Wir wollen analysieren, ob zwei Shared Service Center, die die gleichen Prozesse abbilden, auch ein homogenes Buchungsverhalten an den Tag legen. Durch einen Vergleich der Daten von diesen zwei Shared Service Center können möglicherweise auch Ausreißer festgestellt werden, welche beim Betrachten eines Centers allein gar nicht als solche wahrgenommen werden.
- Wir wollen die Qualität der Stammdaten in einer Kennzahl messbar machen, und so verschiedene Datenbestände vergleichbar machen.
- Es sollen Kunden nach prozessualen Aspekten geclustert werden, nicht nur im Rahmen einer klassischen ABC Analyse. Hierdurch kann ein Verständnis für verschiedene Gruppen von Kunden erzeugt werden, eine Anpassung von eigenen Prozessen auf verschiedene Kundengruppen ist denkbar.
Verpassen Sie nicht den letzten Teil unserer Blog-Reihe! Im nächsten Beitrag zeigen wir Ihnen den Nutzen von Machine Learning an drei verschiedenen Beispielen.