

Die Machine Learning Befehle “Train”, “Predict” und “Cluster” am Praxisbeispiel erklärt
Teil 1 – „Train“ und „Predict“ in „ACL™ Robotics“
In diesem Blogpost zeigen wir Ihnen zwei Beispiele von Vorgehensweisen, wie die Analysesoftware „ACL™ Robotics“ - früher „ACL™ Analytics“ - des Softwarehersteller Galvanize die Umsetzung von Machine Learning ermöglicht. Für Profis: Es werden sowohl Supervised- als auch Unsupervised-Learning Ansätze unterstützt. „ACL™ Robotics“ ist eine Softwarelösung, die schon seit vielen Jahren die manuelle und automatisierte Analyse großer Datenmengen unterstützt. Neben vielen Schnittstellen u.a. zu SAP (via "SAP Connector"), Salesforce, Google Hive, Amazon Redshift, Outlook, PDF-Importen oder beliebigen ODBC-Datenquellen, hilft eine automatisierte Skriptsprache, die Abfolge von Analyseschritten zu automatisieren. Der Hersteller Galvanize ordnet dies dem Bereich RPA (Robotic Process Automation) zu. Einzelne Analyseschritte werden durch Methoden bzw. Kommandos wie Sortierungen, Summenstrukturen, Joins, Relationen oder Verdichtungen wie Kreuztabellen und Summenstrukturen abgebildet, um nur einige Beispiele zu nennen. Zu diesen Kommandos gehören seit geraumer Zeit auch drei, mit deren Hilfe sich Machine Learning Ansätze automatisieren lassen: „Train“, „Predict“ und „Cluster“. Wir bringen Ihnen in diesem Blogpost die Verwendung dieser drei Kommandos näher, anhand von konkreten betriebswirtschaftlichen Beispielen wie etwa der Vorhersage von Retourenwerten und dem Clustering von Kunden im Zusammenspiel mit Zahlungszielen. Für bestehende ACL-Anwender bieten wir zudem die Möglichkeit, ACL-Projekte für die Beispiele herunterzuladen und so jede Methode selbst Schritt für Schritt ausprobieren zu können.
Dieser Blogpost ist auf Grund seiner Länge in zwei Teile aufgeteilt:
- Teil 1 behandelt die Befehle „Train“ und „Predict“
- Teil 2 behandelt den Befehl „Cluster“, welcher auf dem k-Means Algorithmus basiert
Das Beispiel für Teil 1 ist im Bereich Vertrieb angesiedelt: Kunden bestellen Waren unterschiedlichen Wertes, dabei kann es im Tagesgeschäft natürlich auch zu Retouren kommen, sprich die Kunden nehmen aus verschiedenen Gründen Rücksendungen vor und bekommen diese dann im Regelfall erstattet. Wir stellen uns exemplarisch die Frage:
Wie hoch ist der Retourenwert bei einem Bestellwert von 2000€, 4200.50€ oder 65000€?
Mit Hilfe der Kommandos „Train“ und „Predict“ in ACL (siehe Menüpunkt „Machine Learning“) werden wir diese Frage beantworten. In Abbildung 1 sehen Sie 967 Bestell- und Retourenwerte. Ein fiktiver Datensatz dient als Grundlage der Berechnungen. Jeder Punkt in der Grafik repräsentiert eine Bestellung. Der jeweilige Bestellwert wird auf der x-Achse abgetragen, der zugehörige Retourenwert auf der y-Achse. Die Winkelhalbierende in blau gibt den maximalen Retourenwert an, da dieser stets kleiner gleich dem Bestellwert ist. Bestellungen auf der Winkelhalbierenden haben einen Retourenwert gleich dem Bestellwert.

Abbildung 1: 967 Bestellungen und deren Retouren
Workshop:
- Daten downloaden: Öffnen Sie ACL und das Projekt „estimate_returns.acl“ (hier kostenfrei downloaden), dieses enthält zwei Tabellen:
- „orders_and_returns“, dieser Datensatz ist der sogenannte Trainingsdatensatz und enthält die Daten aus Abbildung 1.
- „unseen_orders“, dieser Datensatz enthält die Bestellwerte, für welche wir die Retourenwerte schätzen möchten.
- Modell berechnen: In diesem Schritt wird das Modelltraining durchgeführt. Mit „orders_and_returns“ werden im Folgenden mehrere Modelle trainiert, das heißt verschiedene statistische Verfahren versuchen jeweils den Zusammenhang zwischen den Bestellwerten und den Retourenwerten zu ermitteln. Das Verfahren, welches den Zusammenhang am besten erklärt („The Winning Model“), wird dann verwendet um für die gegebenen Bestellwerte 2000 €, 4200.50€ und 65000€ die Retourenwerte zu schätzen. ACL führt das genannte Vorgehen automatisch durch. Gehen Sie hierzu wie folgt vor: Klicken Sie auf „orders_and_returns“ in der Sidebar, Sie sehen nun die zugehörige Tabelle in der Grundansicht. Unter „Machine Learning“ -> „Train“ kommen Sie zu der Ansicht aus Abbildung 2
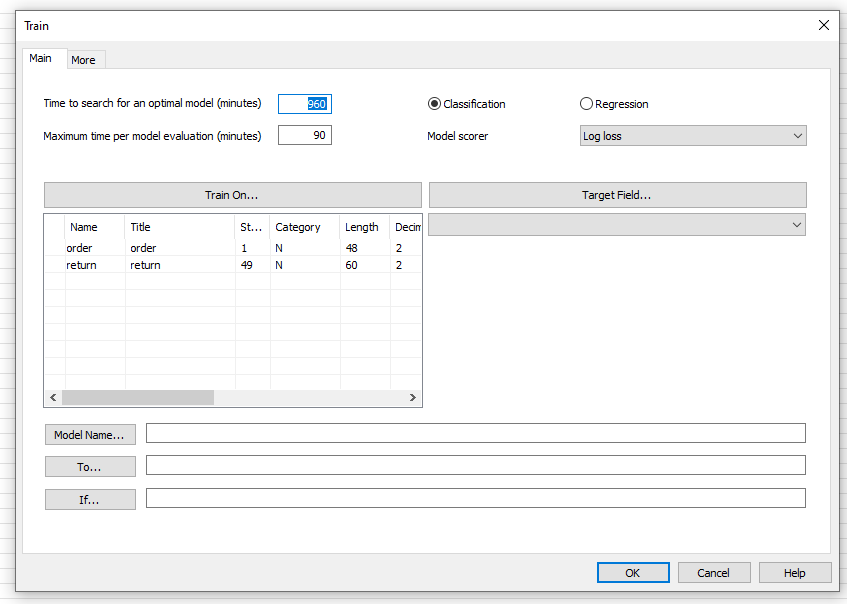
Abbildung 2: Eingabemaske für die Modellsuche
Verändern Sie nun die Parameter und Einstellungen in der Eingabemaske und starten Sie dann die Suche nach dem „Winning Model“ mit „OK“ (vgl. Abbildung 3).
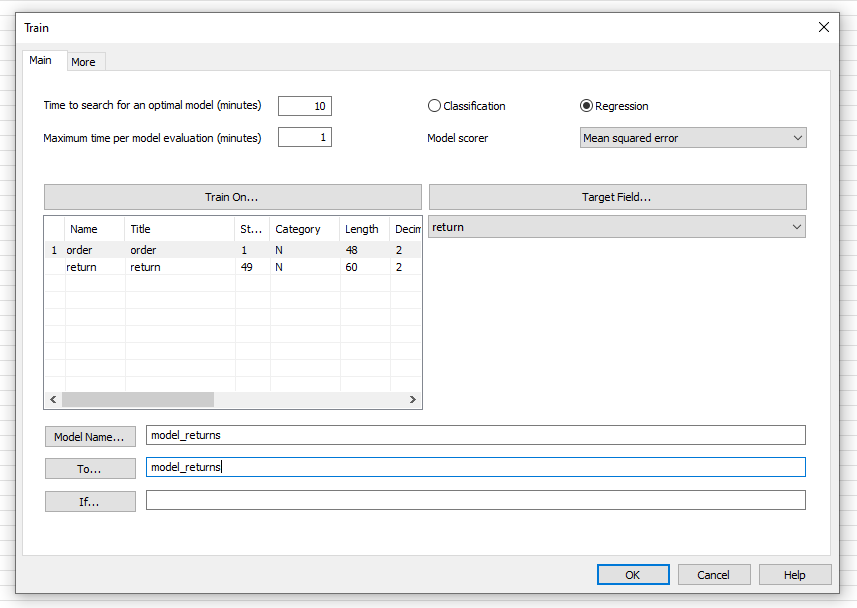
Abbildung 3: Veränderte Eingabemaske für die Modellsuche
- Time to search for an optimal model (minutes)“ bestimmt, wie lange die Suche nach dem „Winning Model“ insgesamt dauert.
- „Maximum time per model evaluation (minutes)“ bestimmt, wie lange jedes einzelne Modell maximal an die Daten angepasst wird. ACL rät, dass die Gesamtzeit mindestens das zehnfache der Evaluationszeit pro Modell entspricht. Generell gilt, je länger die genannten Zeiten gewählt werden, desto besser sind die einzelnen Modelle und somit das „Winning Model“. Die in diesem Beispiel gewählten Zeiten sind im Allgemeinen für größere Datensätze deutlich zu klein. ACL rät zu 45 Minuten pro 100 MB an Daten für die Zeitangabe bei „Maximum time per model evaluation (minutes)“.
- In unserem Beispiel wollen wir eine Regression durchführen, weil ein numerischer Wert, der Retourenwert, geschätzt werden soll. Aus diesem Grund setzen wir die Checkbox „Regression“ aktiv.
- Wie bereits erwähnt, werden bei „Train“ verschiedene Modelle in Betracht gezogen, anschließend wird das Beste ausgewählt. Um dieses Modell wählen zu können, wird jeweils eine Performancezahl zugeordnet, je kleiner diese Zahl ist, umso besser ist das zugehörige Modell. Es gibt verschieden Berechnungsarten für eine Performancezahl, im Dropdownmenü „Model scorer“ können sie sich für eine entscheiden. Es empfiehlt sich, anhand der Ergebnisse, die am besten geeignete Variante zu wählen.
- Unter „Train on…“ wählen Sie die sogenannten „Key“- oder „Feature-Variablen“, also die Variablen, mit denen Sie den Retourenwert schätzen wollen. In unserem Fall gibt es nur eine „Feature-Variable“, aus diesem Grund ist auch nur der Bestellwert markiert. Unter „Target Field…“ bestimmen sie die Variable, welche geschätzt werden soll, in unserem Beispiel wählen wir den Retourenwert.
- Bei „Model Name…“ geben sie den Namen für das Modell ein, mit dieser Bezeichnung wird das Modell nach der Berechnung in der Sidebar gelistet sein.
- Bei „To…“ geben sie den Namen der Tabelle an, welche nach der Berechnung Informationen zum „Winning Model“ enthält. Diese Tabelle wird ebenfalls nach dem Ausführen von „Train“ in ihrer Sidebar gelistet sein.
- Bei „If…“ können Sie optional Einträge aus dem Trainingsdatensatz ausschließen. Unter dem Reiter „More“ können Sie einige Experteneinstellungen vornehmen, für unser Beispiel ist dies aber nicht notwendig.
Sobald ACL das „Winning Model“ bestimmt hat, sehen Sie dies in Ihrer Sidebar durch die erstellte Datei „model_returns“.
3. Retourenwerte prognostizieren: Die Ausgangsfrage lautete: „Wie hoch ist der Retourenwert bei einem Bestellwert von 2000€, 4200.50€ oder 65000€?“ In der Tabelle „unseen_orders“ in Ihrem ACL-Projekt, sind genau diese drei Bestellwerte hinterlegt. „Unseen“ bezieht sich hier darauf, dass das Modell nicht mit diesen Bestellwerten trainiert wurde. Öffnen Sie die genannte Tabelle in ihrer Grundansicht und wählen Sie „Machine Learning“ -> „Predict“. Geben Sie dann das berechnete Modell an, in unserem Beispiel „model_returns.model“, sowie einen Namen für die Tabelle, welche die geschätzten Retourenwerte enthalten soll. Bei „If…“ und „More…“ können Sie optional Einträge beim Prognostizieren ausschließen. (vgl. Abbildung 4)
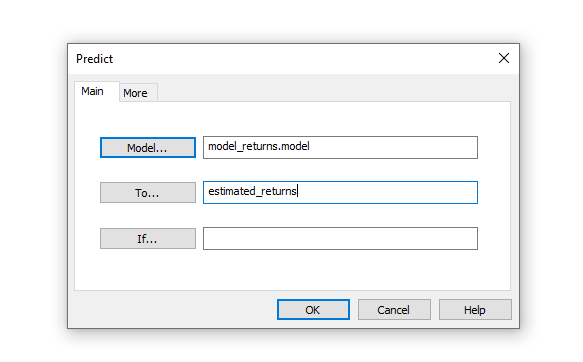
Abbildung 4: Eingabemaske für die Berechnung der Prognosen
Der Datensatz mit dem Sie das „Winning Model“ suchen und der Datensatz, für welchen Sie dann die Werte des „Target-Fields“ schätzen, müssen genau dieselben „Feature-Variablen“ aufweisen. Die Tabelle „estimated_returns“ in ihrer Sidebar enthält nun die Prognosen für die Bestellwerte 2000€, 4200.50€ und 65000€ basierend auf dem „Winning Model“ und dem Trainingsdatensatz. Die gerundeten Prognosen lauten: 796€, 1672€ und 25873€. Abbildung 5 zeigt den Trainingsdatensatz, sowie die drei betrachten Bestellwerte 2000€, 4200.50€ und 65000€ und deren zugehörige Prognosen in Rot.
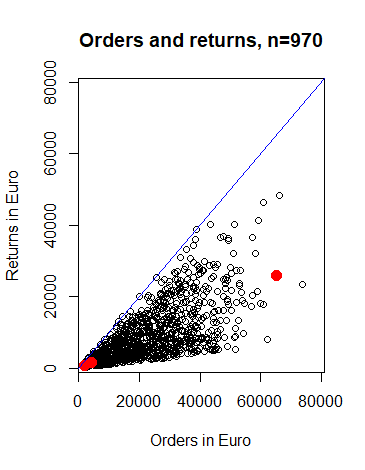
Abbildung 5: Bestellungen und deren (geschätzte) Retouren
Mit Hilfe von „Train“ und „Predict“ haben Sie nun für gegebene Bestellwerte eine Prognose für den Retourenwert berechnet. Um mehr Einblick in das automatische Vorgehen von ACL zu erlangen, wurden in Abbildung 6 die Retourenwerte für Bestellwerte gleich 1000€, 2000€, 3000€,…, 80.000€ berechnet. Für die Prognosen wurde erneut das „Winning Model“ von oben verwendet. Es ist deutlich zu erkennen, dass das „Winning Model“ ein lineares Modell ist, denn die Prognosen liegen auf einer Geraden (vgl. Abbildung 6). Falls der Trainingsdatensatz „orders_and_returns“ verändert wird, ändert sich im Allgemeinen das „Winning Model“ und die zugehörigen Modellparameter. Das „Winning Model“ kann auch ein nicht-lineares Modell sein. Da die Trainingsdaten ausschließlich Bestellungen enthalten, welche retourniert wurden, schätzt das gefundene Modell aus ACL stets den zu erwartenden Retourenwert, falls eine Bestellung retourniert wird. Das Modell schätzt nicht, ob eine Bestellung retourniert wird!
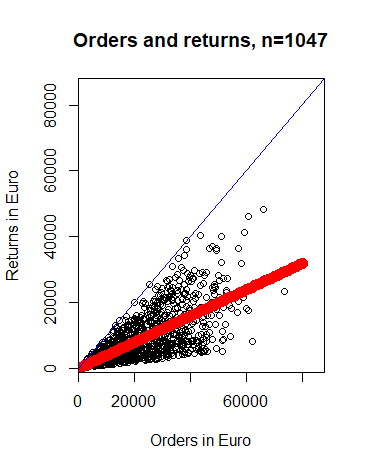
Abbildung 6: Bestellungen, (geschätzte) Retouren mit Andeutung der Regressionsgeraden
Das oben beschriebene Vorgehen wird dem Supervised-Learning zugeordnet. Der Begriff „Supervised“ bezieht sich hier darauf, dass mit Hilfe der „Key-Variablen“ Werte für das numerische „Target-Field“ geschätzt werden. Der vorgestellte Ablauf funktioniert auch mit mehreren „Key-Variablen“, dadurch wird die Anzahl der in das Modell einfließenden Variablen erhöht. Beim Unsupervised-Learning existiert kein „Target-Field“. Im zweiten Teil dieses Blogposts wird ein Beispiel mit einem Unsupervised-Learning Ansatz vorgestellt.
Im ersten Teil dieses Blogposts haben wir Ihnen gezeigt, wie Sie mittels der Kombination von „Train“ und „Predict“ Vorhersagen für Ihre Daten berechnen können. Wenn Sie Ihre eigenen Daten verwenden möchten, lassen sich die notwendigen Schritte abstrahiert wie folgt zusammenfassen:
- Erstellen Sie einen Trainingsdatensatz, dieser enthält stets die „Key-Variablen“ und das „Target-Field“.
- Erstellen Sie einen Datensatz, für welchen Prognosen berechnet werden sollen, dieser enthält dieselben „Key-Variablen“ wie der Trainingsdatensatz.
- Berechnen Sie das „Winning Model“ mit einer geeigneten Parameterwahl.
- Berechnen Sie mit dem „Winning Model“ Prognosen für den Datensatz aus Schritt 2.
Den größten Entscheidungs- bzw. Gestaltungsspielraum haben Sie bei der Wahl der „Key-Variablen“ und der Wahl der Parameter.
Wir hoffen, dass Ihnen dieser Blogpost gefallen hat und wünschen Ihnen viel Spaß beim Ausprobieren der Befehle. Wenden Sie sich bei Fragen gerne jederzeit an uns. Im zweiten Teil, der demnächst veröffentlicht wird, beschäftigen wir uns mit dem „Cluster“-Befehl am Beispiel von Kundenstammsätzen und Zahlungszielen.