

Process Mining Teil 1 - eine umfassende Betrachtung - Grundlagen
Process Mining ist in der Datenanalysewelt seit einigen Jahren ein Thema, mit dem sich Analysten mehr und mehr beschäftigen. Auch wir haben dieser Methodik bereits einen Blogartikel gewidmet und erste Erfahrungen in Projekten verschiedener Größenordnung und mit unterschiedlichen Tools gesammelt. Ich möchte mit dieser Artikelreihe Einblick in unsere gesammelten Erfahrungen geben. Nach der Erklärung einiger Grundbegriffe verdeutliche ich durch einen Blick hinter die Kulissen zwei Punkte:
- Beim Thema Process Mining steht und fällt die Qualität der Ergebnisse und Verarbeitbarkeit durch den Endanwender mit der Qualität der Vorüberlegungen und Konzeption
- Eine sauber definierte und fundiert durchgeführte Datenaufbereitung ist die Basis dafür
Einleitung
Ein erster Blick auf einen durch Process Mining Tools erzeugten Prozessgraphen sorgt in der Regel bei interessierten Entscheidungsträgern dafür, dass Sie schnell Feuer und Flamme für die Materie sind und ein derartiges Tool unbedingt einsetzen wollen. Auch ich war anfangs sehr beeindruckt und konnte es kaum erwarten, mich mit der Technologie bzw. deren Anwendung näher zu beschäftigen. Dies liegt nicht zuletzt auch daran, dass viele Process Mining Anbieter natürlich nur leicht verdauliche, eingängige Bildchen in Ihre Marketingunterlagen packen und die „unangenehme“ Wahrheit sich erst beim zweiten oder dritten Blick offenbart. Diese hässliche Wahrheit wird umgangssprachlich auch gerne als „Nudelsuppe“ oder „Spaghetti“ bezeichnet und lässt sich am besten visuell mit unten stehender Grafik verdeutlichen.

Bild 1 – einfacher Beispielgraph
Abbildung 1 zeigt uns ein wunderbares Bild eines Einkaufsprozesses mit typischen Ereignissen wie Anlage und Freigabe der Bestellung oder Waren- und Rechnungseingang. Die Grafik verschweigt allerdings, dass dieses Prozessmodel nur 15 % der Events beinhaltet, die im Datenbestand vorkommen und zwischen diesen 15 % auch nur die wichtigsten Pfade visualisiert wurden. Die ganze „Grausamkeit“ eines echten und gelebten Prozesses zeigt sich dann in Abbildung 2, die auf dem gleichen Datenbestand basiert, diesmal allerdings 100% der Events und 100% der Pfade darstellt. Es erübrigt sich zu sagen, dass ein Arbeiten bzw. Prüfen anhand einer solchen Informationsgewalt nicht mehr möglich ist. Skeptikern sei gesagt, dass ein solcher Graph in seiner verwirrenden Gesamtheit beileibe kein Einzelfall ist und die verarbeitete Datenmenge aus einem SAP Buchungskreis mit knapp 24.000 Einkaufsbelegköpfen, 53.000 Belegpositionen und jeweils ca. 80.000 Waren- und Rechnungseingängen besteht und somit eher im Bereich der „kleineren“ Datenmengen anzusiedeln ist.

Bild 2 - die "Nudelsuppe"
Der Fairness halber muss hier erwähnt werden, dass diese absolute Unordnung größtenteils dadurch zustande kommt, indem man sich 100% der Pfade einblendet. Wenn man, was die gängigen Tools zum Glück ermöglichen, den Detailierungsgrad der Pfaddarstellung reduziert, sieht das Bild in der Regel schon wieder freundlicher aus, wie Abbildung 3 zeigt. Hierbei handelt es sich nun um eine Darstellung ALLER Events, mit jedoch nur den wichtigsten Pfaden (in meinem Beispiel sind es 10 %).

Bild 3 – Prozessbild - 100% Events - 10% Pfade
Abbildung 3 zeigt, dass für diesen Einkaufsprozess relativ viele unterschiedliche Events existieren, was daran liegt, dass Rechnung- und Wareneingänge durchnummeriert wurden. D.h. wenn für eine Bestellposition fünf verschiedene Rechnungseingänge existieren, wurden auch fünf verschiedene Ereignisse (Rechnungseingang #1 bis #5) generiert. Dies erhöht natürlich die Anzahl vorhandener Events, bietet aber wesentlich mehr Prozesstransparenz und vermeidet ein Problem des Process Mining, das ich hier mal als „repetitive“ Ereignisse bezeichnen möchte. Das sind Ereignisse, die direkt auf sich selbst folgen und in der Regel dann mittels eines Pfeils auf sich selbst dargestellt werden (Abbildung 4).
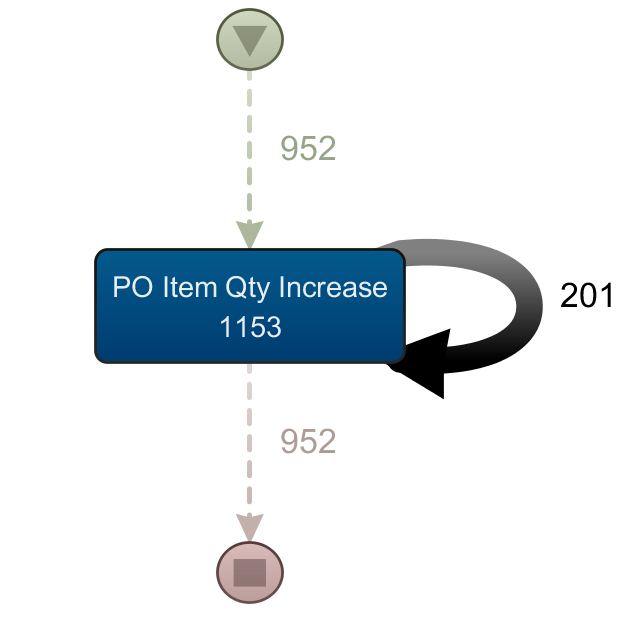
Bild 4 – repetitives Ereignis
Diese repetitiven Ereignisse und der Umgang mit Ihnen soll später in einem der Folgeposts noch ausführlicher behandelt werden. Vorher wollen wir noch ein paar grundlegende Begriffe und die Frage des hier verwendeten Tools klären.
DISCO – das hier verwendete Tool meiner Wahl
Der Markt der Process Mining Lösungen ist ein zwar wachsender, aber noch überschaubarer. Wer sich einen unabhängigen Blick verschaffen möchte, der sei auf diesen Wikipedia Artikel verwiesen. Ohne dass ich mich mit allen Tools im Einzelnen auseinander gesetzt habe, und diese nicht wirklich bewerten kann, habe ich bei meinen Ausflügen ins Gebiet des Process Mining das Produkt „Disco“ der Firma Fluxicon verwendet. Zum einen ist das Tool leicht auf einen Standardrechner zu installieren, da es weder eine Serverkomponente noch eine Datenbank benötigt und zum anderen lässt sich damit sehr intuitiv arbeiten, auch wenn man auf diesem Gebiet noch keine große Erfahrung hat.
Ein paar Begriffsklärungen
Bevor wir in den Folgeartikeln in tiefere Details einsteigen werden, erachte ich es als wichtig, einige Begriffe im Vorfeld näher zu erläutern, die uns in dieser Artikelserie immer wieder begegnen werden
- Eventlog
- Event (bzw. Fall oder Case)
- Die Case-ID
Das Eventlog
Die Datenbasis eines Process Mining Projektes ist immer das sogenannte Eventlog. Dieses beinhalteteine - nicht zwangsläufig in sortierter Reihenfolge vorliegende - Auflistung aller Ereignisse des Prozesses, oder besser gesagt, der Ereignisse, die man in seiner Datenaufbereitung definiert hat. Dabei stellt jedes Ereignis pro Fall (wir gehen gleich noch näher auf den Begriffe „Case“ bzw. „Fall“ ein) einen Datensatz dar, der mit mindestens den folgenden Spalten versehen sein muss:
- Der Fall-ID oder Case-ID (sieht unten)
- Der Ereignisart (z.B. Bestellfreigabe, Preisänderung etc.)
- Einem Zeitstempel, wann die Aktivität ausgeführt wurde.
Zusätzlich zu diesen drei notwendigen Spalten, kann man sich zusätzliche Felder definieren, die dann später z.B. für eine weitere Filterung innerhalb der Graphen verwendet werden können. Außerdem ist es denkbar, sofern der Datenbestand dies ermöglicht, mit Start- und Endzeitpunkt bei Ereignissen zu arbeiten, um dies später auch entsprechend in der Software zu visualisieren.
Das Event
Wie bereits erwähnt, besteht das Eventlog aus den einzelnen Ereignissen des Prozesses, den man betrachtet. Die Definition dieser Events und die entsprechende Umsetzung in der Datenaufbereitung ist die erste Herausforderung, der man sich stellen muss. Ohne dabei einen Anspruch auf Vollständigkeit zu erheben, haben wir für unser Procurement-Beispiel folgende Events definiert:
- Anlage einer Bestellanforderung
- Freigabe oder Ablehnung der Bestellanforderung
- Anlage der Bestellung bzw. der jeweiligen Bestellposition
- Freigabe oder Ablehnung der Bestellung
- Preis- oder Mengenanpassungen
- Wareneingang bzw. dessen Stornierung
- Rechnungseingang bzw. dessen Stornierung
Punkt 3) verdeutlicht, dass es schon mal gar nicht so leicht ist, bei den Ereignissen festzulegen, ob man auf Kopf oder Positionsdaten abzielt. Dies wird gerade für den nächsten Begriff – der Case-ID – aber von zentraler Bedeutung sein und wird uns im Laufe dieser Serie auch noch weiter beschäftigen.
Der Case und die Case-ID
Hat man definiert welche Ereignisse man im Prozess visualisieren will, wird man mit dem nächsten Problem konfrontiert: der Definition des Falls (Case) an sich. Jeder eigenständige Prozessdurchlauf, also in unserem Beispiel idealerweise eine Bestellanforderung, die später in Waren- und Rechnungseingang mündet, benötigt einen eindeutigen Schlüssel, die sogenannte Case-ID. Abhängig von der Festlegung was als Fall/Case gesehen wird und der Wahl dieser Case-ID kann sich der Graph später unterschiedlich verhalten. Dass das Festlegen der Case-ID keine triviale Angelegenheit ist, verdeutlichen folgende Überlegungen auf Basis von SAP-Einkaufsdaten.
- Eine Bestellanforderung hat per se keine separaten Kopfdaten in SAP und ist somit immer zeilenbezogen.
- Aus einer Bestellanforderung können mehrere Einkaufsbelegpositionen erzeugt werden, es können jedoch auch mehrere Bestellanforderungen zu einer Einkaufsbelegposition zusammengefasst werden.
- Freigaben von Bestellungen finden grundsätzlich auf Kopfebene statt.
- Änderungen von Preis oder Menge sind selbstverständlich positionsbezogen.
- Wareneingang und Rechnungseingang sind ebenso positionsbezogen und können natürlich in einer 0-n Relation auftreten, d.h. eine Bestellbelegposition kann mehrere Wareneingänge und Rechnungseingänge haben.
Dies verdeutlicht, dass es durchaus schwierig ist, zum einen den Case an sich festzulegen (Bestellkopf oder Bestellposition?) und zum anderen die entsprechenden Ereignisse einer eindeutigen Fall-ID zuzuordnen.
Auch diesem Problem werden wir uns in der Artikelserie noch genauer widmen, in dem wir später unterschiedliche Konstellationen miteinander vergleichen und die Auswirkungen im Process Mining Tool betrachten.
Die Beispieldaten
Es handelt sich dabei, wie bereits erwähnt, um einen für SAP®-Mandanten eher kleineren Datenbestand mit folgendem Mengengerüst.
- 24.000 Bestellungen mit 53.000 Belegpositionen
- Jeweils 80.000 Rechnungs- und Wareneingänge
- Ca. 15.000 Bestellanforderungen
Ich habe mich für diesen Artikel im ersten Schritt bewusst dafür entschieden, die komplette FI-Seite außen vor zu lassen und mit Rechnungseingang, bzw. den entsprechenden MM-Transaktionen von SAP® zu enden. Eine Hinzunahme der FI-Transaktionen inkl. Ausgangszahlungen und der SAP®-Ausgleichssystematik in Ihrer ganzen Flexibilität, hätte hier eine Komplexität erzeugt, die dem Erarbeiten erster Grundlagen nicht förderlich gewesen wäre.
Der Ausblick
Auf folgende Themen werde in meinen nächsten Posts näher eingehen:
- Herausforderungen bei der Falldefinition (Kopf vs. Position bzw. was wird das führende Element
- Timing bzw. richtige zeitliche Abgrenzung
- Besonderheiten beim Definieren bzw. Erstellen einiger Ereignisse
- Möglichkeiten von DISCO
- Frequenz- vs. Performancedarstellung
- Möglichkeiten der Filterung
- Das Arbeiten mit Ressourcen bzw. weiteren Datenfeldern
Zu guter Letzt hat sich Dr. Anne Rozinat vom DISCO-Hersteller Fluxicon bereit erklärt diese Serie mit einem Gastartikel zu bereichern, in dem sie von konkreten Projekterfahrungen berichtet.
Ich freue mich auf Ihr Feedback und weitere Anregungen zum Thema Process Mining.