

CCM (Teil 3) - 5 Dinge, die Sie wissen sollten - und 2 Dinge, die Sie besser nicht vergessen - beim Aufbau einer CCM Datenanalyseumgebung
Dieser Blogbeitrag ist der dritte aus einer mehrteiligen Serie, die betitelt ist mit „5 Dinge, die Sie wissen sollten - und 2 Dinge, die Sie besser nicht vergessen - beim Aufbau einer CCM Datenanalyseumgebung“. Es geht um Datenanalyse-Projekte im Allgemeinen, mit einem Fokus auf der Einführung komplexerer Lösungen, wie etwa einem CCM (Continuous Controls Monitoring) System.
Dieser Artikel besteht aus mehreren Teilen. Die ersten fünf Teile beschreiben Punkte, mit denen man im Zusammenhang mit Datenanalyseprojekten vertraut sein muss:
- Wissen, was man wissen möchte (Analytische Fragestellungen auflisten)
- Wissen, mit welchen Systemen man es zu tun hat? (Datenquelle(n) identifizieren)
- Wissen, wie die Daten strukturiert sind (Datenstruktur erarbeiten)
- Wissen, was die Analysetools können (Technische Möglichkeiten und Grenzen verstehen
- Wissen, wer die “Internen Kunden” sind (Ergebnisempfänger, Umfang und Format festlegen)
Die Teile sechs und sieben beinhalten zwei Aspekte, die zwar bestimmt bekannt, aber so wichtig sind, dass wir sie hier nochmal ansprechen wollen:
- Es wird Geld kosten (Stichwort „Budget“)
- Man braucht jemanden, der dies alles umsetzen kann (Stichwort „Personelle Ressourcen“)
Die ersten beiden Artikel sind bereits erschienen (alle bereits veröffentlichten Teile sind oben verlinkt, so dass Sie jederzeit auch die Historie nachlesen können). Dies ist nun der dritte Teil „Wissen, wie die Daten strukturiert sind“:
Fünf Dinge, die Sie wissen sollten, Fortsetzung (3/5)
Wir fahren fort mit dem dritten der fünf Punkte, die ich persönlich als „essentiell“ ansehe. Schritt eins, betitelt mit „Wissen, was Sie wissen möchten“, drehte sich darum, die Geschäftsprozesse zu verstehen und darauf aufbauend eine Fragestellung möglichst detailliert zu erarbeiten sowie zu beschreiben. Dies war die Basis dafür, diese auch wirklich konkret beantworten zu können. Nur durch genaue inhaltliche Durchdringung der betrieblichen Abläufe können die Analyseanforderungen entsprechend gut formuliert werden. Wir hatten als Beispiel ein Thema herangezogen, das man dem Bereich „Compliance“ zuordnen kann: „Zahlungen in kritische Länder“. Die konkreten Fragen, die sich daraus ergaben, wurden wie folgt beschrieben:
- Erstelle eine Liste von Ausgangszahlungen an Kunden oder Lieferanten.
- Prüfe, ob es zu Zahlungen ohne Geschäftspartner gekommen ist („Aufwand an Bank“).
- Für diese Ausgangszahlungen soll das Bankland des Zahlungsempfängers identifiziert werden.
- Im Kern der Analyse wird das Land, in das die Zahlung geleistet wurde, mit der Liste von Ländern abgeglichen, die auf Grund von CPI/Embargo oder Steueraspekten als kritisch definiert wurden.
Im zweiten Artikel wurde erklärt, wie wichtig es ist zu „wissen, mit welchen Systemen man es zu tun hat“. In unserem fiktiven Beispiel konnten wir herausfinden, dass unsere Zahlungstransaktionen sich auf einem SAP® System „SY2“ mit Release SAP® ERP ECC 6.0 befinden, da dort die Buchhaltung für alle Teilgesellschaften weltweit zentral abgewickelt wird.

Bild 1 - Wissen, mit welchem System man es zu tun hat
Basierend auf dieser Information wurde der “Data owner” identifiziert, und wir konnten entsprechend Zugangsdaten (User mit korrektem Berechtigungsprofil und Nur-Lesezugriff auf die Daten) anfordern.
Nun kennen wir das System und haben Zugriff darauf. Aber welche Daten brauchen wir nun konkret? Darum geht es nun in diesem Kapitel, das betitelt ist mit “Wissen, wie die Daten strukturiert sind”.
Aspekt 3: Wissen, wie die Daten strukturiert sind
Sich Wissen über die Daten anzueignen, erfordert betriebswirtschaftliches Wissen, IT- und Prozess-Know-How. Mit der folgenden Abbildung haben wir im letzten Kapitel das Schichtenmodell einer klassischen Applikation besprochen, und betont, dass die Daten letzten Endes in einer Datenbank gespeichert werden.
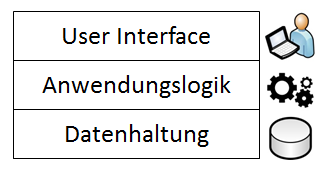
Bild 2 - Schichtenarchitektur (3 Schichten)
Die Datenbank wiederum besteht aus einer Sammlung von Tabellen, in denen die unterschiedlichen Daten abgelegt sind. Eine Tabelle beinhaltet Informationen, die in Form von Spalten (auch Felder genannt) und Datensätzen (oder Zeilen genannt) gespeichert sind. Zum Beispiel könnten Lieferantenadressen in einer Tabelle wie folgt aussehen:

Bild 3 - Strukturierte Ablage von Daten in Tabellen
In unserer kleinen Beispieltabelle befinden sich drei Zeilen Jede Zeile besteht aus demselben Set an Spalten, die helfen, die Daten zu strukturieren. Wie schon angesprochen kann eine Datenbank sehr viele Tabellen beinhalten. In einem System wie SAP® ERP ECC 6.0 gibt es mehrere zehntausend davon. Umso wichtiger ist die Frage, welche Daten wir daraus denn nun konkret benötigen?
Dies kann wiederum top-down erarbeitet werden, in dem man folgende zwei Fragen beantwortet:
- In welchen Tabellen befindet sich die Information, die wir für unsere Analysen benötigen?
- Welche konkreten Spalten benötigen wir für die Beantwortung unserer Fragestellung?

Bild 4 - Von der Datenbank zu den Tabellen bis hin zu den Feldern
Schon das Identifizieren der Tabellen kann eine zeitaufwändige Angelegenheit sein, da dies nicht immer unbedingt sofort ersichtlich ist. Was helfen kann ist das Verständnis, dass oft bestimmte Prozessschritte mehr oder weniger direkt einzelnen Tabellen zugeordnet werden können. Untenstehende Grafik zeigt SAP® Tabellen die Daten aus dem Modul SAP®-FI (bzw. SAP®-AP, der Kreditorenbuchhaltung) beinhalten. Manchmal sind dabei Daten auch redundant gespeichert, und die mehr oder weniger selben Informationen in mehr als einer Tabelle abgelegt.

Bild 5 – P2P Prozess mit zugehörigen Tabellen
Ein offener Kreditorenposten in SAP®-FI wird unter anderem in SAP®-FI GL, also dem Hauptbuch (Tabellen BKPF und BSEG) sowie parallel in SAP®-FI AP, dem Nebenbuch der Kreditoren (Tabelle BSIK) gespeichert. Eine Zahlung, die über den automatischen Zahllauf ausgeführt wird, wird im Tabellenpaar REGUH und REGUP gespeichert; der ausgeglichene Posten und die Zahlung sind wiederum in BKPF/BSEG (SAP®-FI) und BSAK (SAP®-AP) zu finden.
Auch wenn es den Anschein haben mag, will ich an dieser Stelle nicht mit einer Endlosaufzählung an Tabellennamen Verwirrung stiften. Die Botschaft ist jedoch, dass aus möglicherweise tausenden Tabellen diejenigen identifiziert werden müssen, die für die jeweilige Analyse wichtig sind. Technisch gesehen gibt es viele Wege, die zu Grunde liegenden Tabellen einer Datenbank zu identifizieren. Ein Weg kann sein, sich mittels Literatur einen Überblick zu verschaffen. Wir haben dazu vor etwa zwei Jahren ein Buch geschrieben, das solche Informationen liefert. Wenn Sie eher ein Freund der Onlinerecherche sind, so hat sich auch hier viel getan, etwa auf der Seite www.erpgenie.com, wo auch Informationen über SAP® Tabellen zu finden sind. Natürlich gibt es auch Wege, wie direkt in SAP® solche Tabellennamen ermittelt werden können. Es würde den Rahmen sprengen, technisch hier alles aufzuzählen im Rahmen dieses Beitrages. Exemplarisch sehen Sie hier einen Screenshot, der die Ermittlung der Tabelle LFBK zeigt, die die Lieferantenbankverbindungen enthält. Ermittelt wurde dies durch Drücken von „F1“ in einem GUI Feld der SAP® Transaktion XK03, und Auswahl des dort angebotenen Menü-Icons „Technische Informationen“.

Bild 6 – “Technische Info”-Screen in SAP® ERP ECC 6.0
Fazit ist, dass es viele Wege gibt, wie die richtige Tabelle ermittelt werden kann. In der Regel bedarf es dazu einer Mischung aus verschiedenen technischen Ansätzen und Wissens.
Was nun als “relevant” erachtet wird, hängt direkt von unserer analytischen Fragestellung bzw. der zur Beantwortung notwendigen Schritte ab. Wenn wir die Prozesse „Purchase-to-Pay“ oder „Order-to-Cash“ komplett abdecken wollen, benötigen wir dazu derzeit etwa 200 SAP® Tabellen. Wenn wir dagegen nur Doppelzahlungen analysieren, reichen schon 8-10 Stück aus.
Zudem sollte man sich bewusst sein, dass möglicherweise manch interessante Aspekte gar nicht im System bzw. in einer Tabelle gespeichert werden. Bezugnehmend auf unser Beispiel sind hier Zahlungen zu nennen, die vollständig manuell, also außerhalb des Systems, angestoßen wurden, ohne dass beispielsweise der automatische Zahllauf benutzt wurde. Eines der größten Risiken in diesem Zusammenhang – neben der Frage, wie die Zahlung denn genehmigt wurde – ist, die offene Frage, wohin das Geld überwiesen wurde bzw. wer der Zahlungsempfänger war. Die Bankdaten des Zahlungsempfängers werden für solche manuellen Transaktionen nämlich nicht aufgezeichnet, wodurch solche Vorgänge sehr intransparent und möglicherweise risikobehaftet sind.
Für die Beantwortung unserer Frage “Zahlungen in kritische Länder” werde ich nun exemplarisch einige Beispiele an Tabellen aufführen, die für die Verdeutlichung der Vorgehensweise ausreichend sind. Würden wir die Frage hier detailliert aufarbeiten, wäre das natürlich jederzeit möglich – es sind dann nur viel mehr Daten nötig. In der Regel bestimmt der Detailgrad das Mengengerüst der Daten.
| Element / Prozessschritt | Tabelle | Bemerkung |
| Globaler Lieferantenstamm | LFA1, LFBK | LFA1 beinhaltet die globalen Lieferantenstammdaten; LFBK die Bankverbindungen je Lieferant. |
| Globaler Kundenstamm | KNA1, KNBK | KNA1 beinhaltet die globalen Kundenstammdaten; KNBK die Bankverbindungen je Kunde. |
| Transaktionen des automatischen Zahllaufs | REGUH | In Tabelle REGUH sind die Bankdaten der Zahlungsempfänger gespeichert, etwa Bankland, Bankschlüssel und Bankkontonummer. Dies wird auf Ebene der einzelnen Zahltransaktionen gespeichert, die für Kunden und Lieferanten durchgeführt wurden. |
| Manuelle Zahlvorgänge | ? | Vielleicht wird das Banking Modul von SAP® benutzt, bzw. der „elektronische Kontoauszug“. Dann könnte die Möglichkeit bestehen, dass die fehlenden Informationen bezüglich manueller Zahlungen in den dafür relevanten Tabellen dort ermittelt werden können. Hier ist in unserem Beispiel Rücksprache mit dem Fachbereich nötig. |
Bild 7 - Die notwendigen Daten erarbeiten: Tabellen
Nachdem die wichtigsten Tabellen identifiziert wurden, müssen wir festlegen, welche Felder wir zur Beantwortung unserer Analyseansätze benötigen. Dies erfordert ein genaues Verständnis der Fragestellung und auch der Vorgehensweise bei der Beantwortung.
Wir interessieren uns für “Zahlungen in kritische Länder”. Dafür konnten wir bereits ermitteln, dass unter anderem in Tabelle REGUH die Zahlungstransaktionen gespeichert sind inklusive der Kontoverbindung des Zahlungsempfängers. Nun ist es wichtig zu wissen, dass die Tabelle REGUH nicht nur ein Länderkennzeichen enthält, das in Frage kommen könnte, sondern gleich drei Stück davon. Ein Feld ist bezeichnet mit „LAND1“ und steht für das Land des Lieferanten oder Kunden; ein anderes ist mit „ZLAND“ bezeichnet, und beinhaltet das Land des Zahlungsempfängers (der ja durchaus vom Lieferanten oder Kunden abweichen kann!). Ein drittes Feld namens „ZBNKS“ beinhaltet ebenfalls einen Länderschlüssel, bei dem es sich um das Land der Bank handelt, bei der das Konto geführt wird. Welches dieser drei Felder sollen wir nun verwenden, um die Zahlungstransaktionen mit unserer Liste kritischer Länder zu vergleichen, die auf dem CPI (Corruption Perception Index) oder einer Embargoliste, HADDEX oder ähnlichem basiert? Je nachdem, für welches Feld wir uns entscheiden, beantworten wir verschiedene Fragen:
- Welche Zahlungen wurden durchgeführt für Lieferanten oder Kunden, die ihren Sitz in einem „kritischen“ Land haben?
- Welche Zahlungen wurden durchgeführt für Lieferanten oder Kunden, bei denen der Zahlungsempfänger den Sitz in einem „kritischen“ Land hat?
- Welche Zahlungen wurden an eine Kontoverbindung durchgeführt, die in einem kritischen Land geführt wird, egal wo der Geschäftspartner oder Zahlungsempfänger seinen Sitz hat?
Wenn wir den Faden weiterspinnen wollten, könnten wir die Stammdaten der Kunden und Lieferanten noch mit einbeziehen, aber ich denke, die Botschaft ist klar: Wie beschrieben bedarf es einer möglichst genau gestellten Frage, um die für die Antwort notwendigen Daten bzw. Datenstrukturen zu erarbeiten, die wir benötigen. Natürlich könnten wir, auch wenn wir uns für Option drei mit „ZNBKS“ entscheiden, die anderen Länderschlüssel trotzdem im Ergebnis zu Informationszwecken mitführen.
| Element / Prozessschritt | Tabelle | Feld(er) | Bemerkung |
| Lieferantenstamm global | LFA1 | LIFNR | Lieferantennummer |
| Lieferantenstamm global | LFA1 | LAND | Stizland Lieferant |
| Lieferantenbankverbindungen | LFBK | LIFNR | Lieferantennummer |
| Lieferantenbankverbindungen | LFBK | BANKS | Bankland |
| Kundenstamm global | KNA1 | KUNNR | Kundennummer |
| Kundenstamm global | KNA1 | LAND1 | Sitzland Kunde |
| Kundenbankverbindungen | KNBK | BANKS | Bankland |
| Kundenbankverbindungen | KNBK | KUNNR | Kundennummer |
| Transaktionen automatischer Zahllauf | REGUH | LIFNR | Lieferantennummer |
| Transaktionen automatischer Zahllauf | REGUH | KUNNR | Kundennummer |
| Transaktionen automatischer Zahllauf | REGUH | LAND1 | Sitzland |
| Transaktionen automatischer Zahllauf | REGUH | ZLAND | Sitzland Zahlungsempfänger |
| Transaktionen automatischer Zahllauf | REGUH | ZBNKS | Bankland Zahlungsempfänger |
| ... | ... | ... |
Bild 8 - Die notwendigen Daten erarbeiten: Felder
Nicht nur das Identifizieren der Tabellen und Felder ist notwendig, auch die Kenntnis über die Zusammenhänge ist oft von Bedeutung. So kann ein Kunde oder Lieferant durchaus keine, genau eine oder auch mehrere Bankverbindungen haben; sprich in Tabelle KNBK und LFBK finden sich möglicherweise mehrere Einträge zur selben Lieferanten- oder Kundennummer. Oder gar kein Eintrag, falls die Zahlungen ausschließlich durch Schecks abgewickelt werden. Also sollten neben der Struktur und Bedeutung der Tabellen auch die Zusammenhänge zwischen den Tabellen erarbeitet werden. Diese sind in relationalen Datenbanken mittels Primär- und Fremdschlüsselbeziehungen abgebildet. Ohne an dieser Stelle technisch weiter ins Detail zugehen sei betont, dass nur wenn diese Aspekte bekannt sind, man größtmöglichen Nutzen bei Analysen aus den Daten ziehen kann.
Am Ende von Schritt drei sollte also eine möglichst komplette Liste von Tabellen und Feldern stehen, die wir für die Analysen benötigen. Darin befinden sich nicht nur Felder, die für den jeweiligen Analysealgorithmus benötigt werden, sondern auch Zusatzinformationen wie die Kunden- der Lieferantennummern, der Name des Geschäftspartners, der Name des Zahlungsempfängers, etc. Oft wird aus diesem Grund die Liste der benötigten Tabellen und Felder schnell wachsen und umfangreich werden. Je mehr Details man wissen und analysieren möchte, desto umfangreicher wird die entsprechende Tabellen- und Feldliste sein. Jedoch sollte man auch - unter anderem aus Gründen des Datenschutzes, aber auch zwecks Performance und Verständlichkeit der Ergebnisse – Datensparsamkeit walten lassen wo immer möglich.
Wenn wir unsere “5 Punkte” als Art Checkliste zu Grunde legen, haben wir damit die ersten drei Punkte erfolgreich klären können:
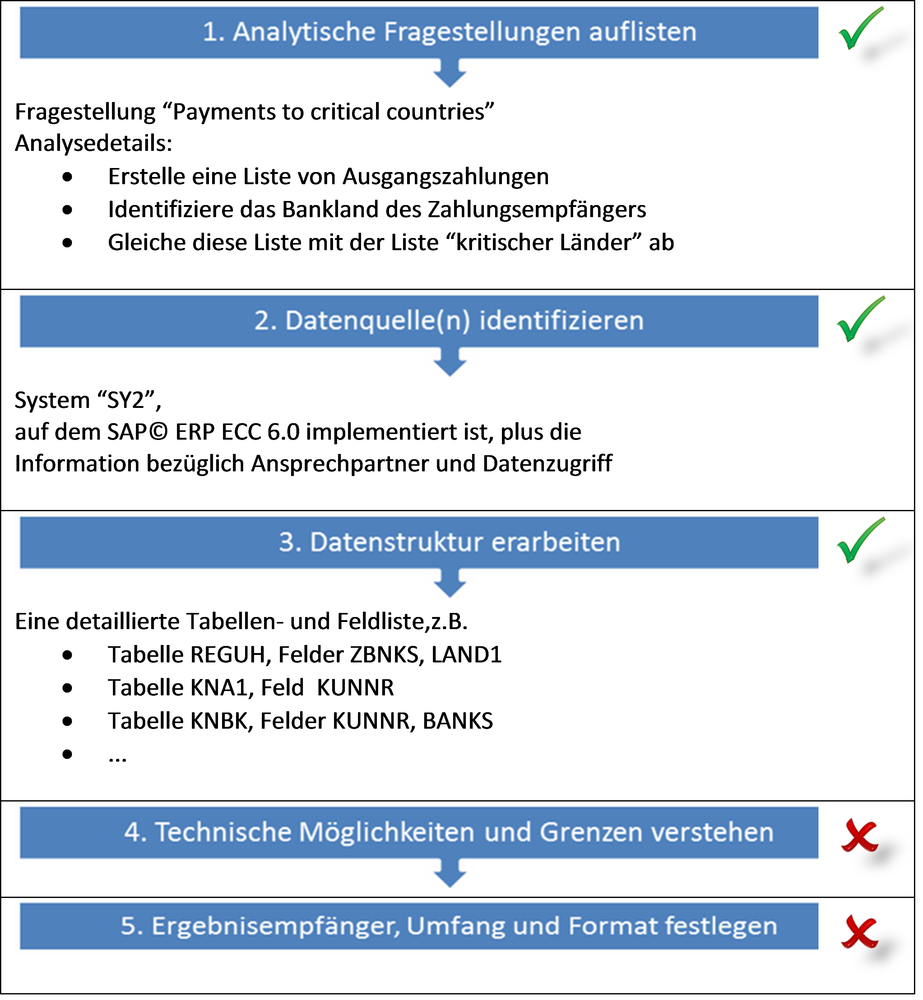
Bild 9 - Die ersten drei Punkte wurden erarbeitet
Nachdem nun die Datenstrukturen erarbeitet und die notwendigen Daten identifiziert wurden, können wir mit der eigentlichen Datenanalyse beginnen. Dafür müssen wir uns mit den vorhandenen Datenanalysetools, ihren Möglichkeiten aber auch Beschränkungen vertraut machen. Wir beschäftigen uns damit im Abschnitt “ Wissen, was die Analysetools können” – also bis nächste Woche, an gleicher Stelle! :-)
Ich hoffe, der dritte Teil unserer Serie „Start eines CCM-Projekts“ hat Ihnen gefallen! Für Fragen oder Kommentare können Sie sich gerne unter info@dab-gmbh.de an uns wenden.
Um den Autor zu kontaktieren, bieten sich auch LinkedIn oder XING an (möglicherweise müssen Sie sich erst einloggen in das entsprechende Social Network, bevor Sie die folgenden Links nutzen können):
LinkedIn: http://de.linkedin.com/pub/stefan-wenig/54/1b8/b30